记一次 k8s apiserver watch hang 问题排查
问题背景
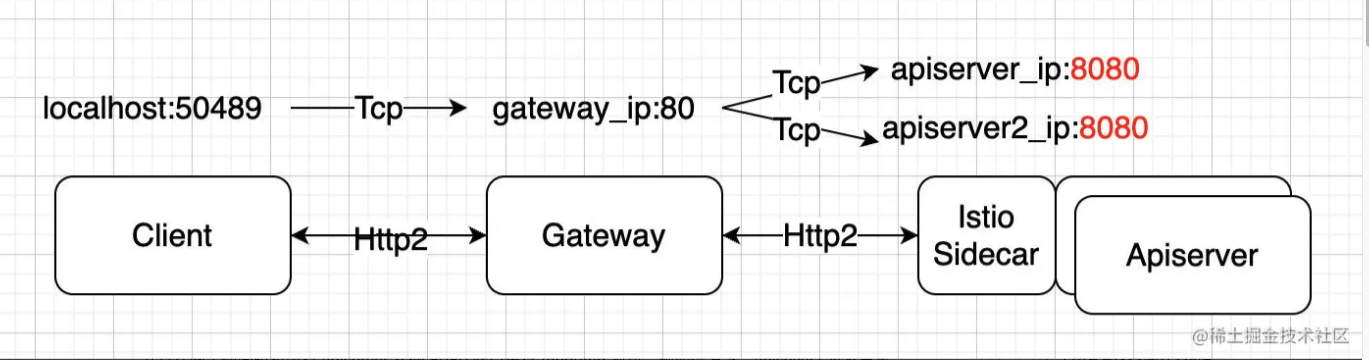
传统的 kubernetes apiserver 请求访问链路为客户端直连 apiserver,为了做 apiserver 高可用,通常我们会给 apiserver 前端再套一层4层或7层代理做多个 apiserver 实例的负载均衡。
在我们的场景下,使用了 istio 的 ingressgateway 作为 client -> apiserver 这条链路中的7层代理。链路变成了 client -> ingressgateway -> apiserver ,gateway 暴露 80 端口供客户端访问, 同时通过 istio virtualService + destinationRule 规则配置 gateway 能通过域名访问到 apiserver 6443 端口,从而实现流量路由。
具体链路如下图所示,
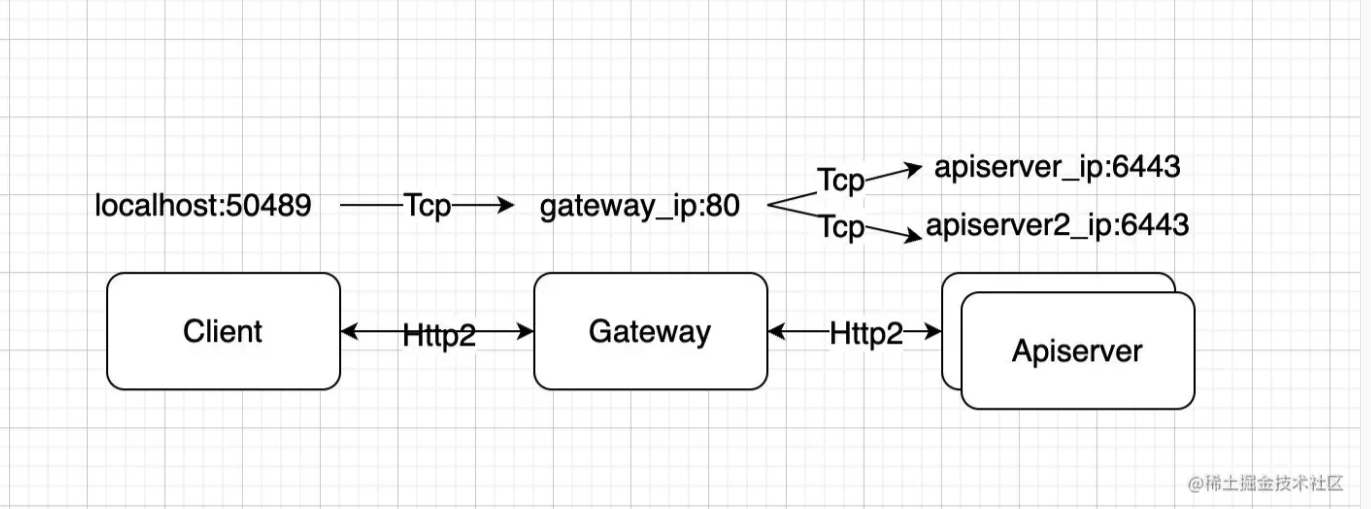
在这样的链路下,我们遇到了如下问题,
在 k8s apiserver 1.18 版本的集群在滚动重启过出现部分组件无法 watch 到事件的情况,客户端 watch 请求偶发 503。需要重启组件,重建 watch 连接才能恢复。
问题现象
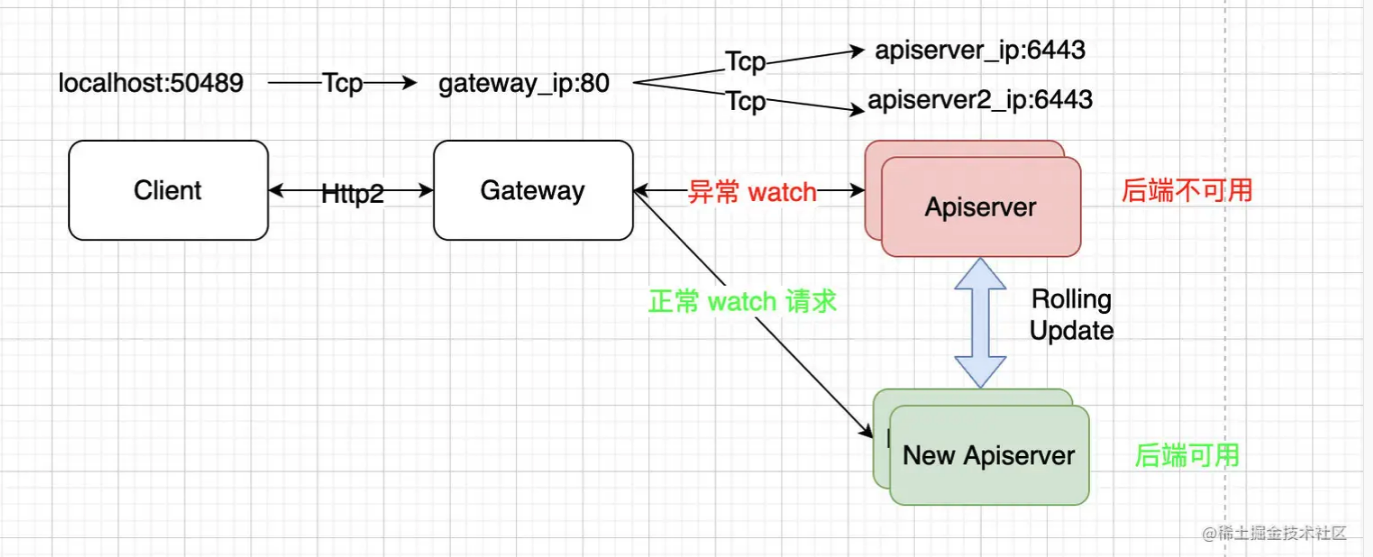
由于 k8s watch 请求是 http2 协议, 故 client 与 gateway 之间保持了长连接,同时 gateway 与后端也保持长连接。
当 apiserver 发生滚动重建后,gateway 与旧 apiserver 连接断开,同时与新 apiserver 建连。此时 client 与 gateway 仍然保持着原来那根连接,故在不重建 7 层 http2 连接的情况下,请求没法打到 new apiserver。
故客户端虽然与 Upstream 网关连接正常,但网关与 apiserver 侧可能仍使用到旧 apiserver 的连接对,导致无法 watch 到事件。
具体现象为
- 客户端出现 watch 请求 hang 住, 偶发出现 watch 请求 503, 报错为:
server is currently unable to handler the requests
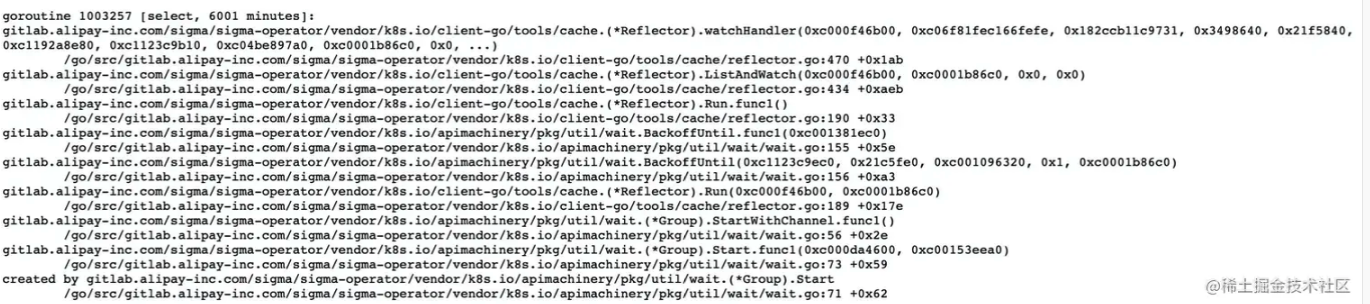
- 通过 pprof 查看到 client-go ListAndWatch 函数中的
watchHandler执行了 6000+ 分钟, 实际应该在 5-10 分钟后就退出重连。
排查过程
首先我的疑点是网关侧(ingressgateway)配置不正确导致了网关和旧 apiserver 连接仍保持,从而导致了客户端(client) watch 请求没有打到新 apiserver 上,但网关侧没有了现场更多信息,且线上 apiserver 集群不能频繁重启,故尝试用风险较低的场景复现问题。
环境
- 两台 apiserver 实例(apiserver1、apiserver2)
- 一台网关实例 (ingressgateway1)
- 个人PC启动 k8s client
复现
线下调试集群 apiserver (之后简称该集群为 staging 集群)请求一共有2实例, 脱敏考虑,我们简写其 ip 为 apiserverIp1、apiserverIp2

1. 新建调试网关, 隔离线上流量
先在生产环境单独起了一个 ingressgateway 网关实例,用于隔离线上流量,仅接收我的本地调试流量

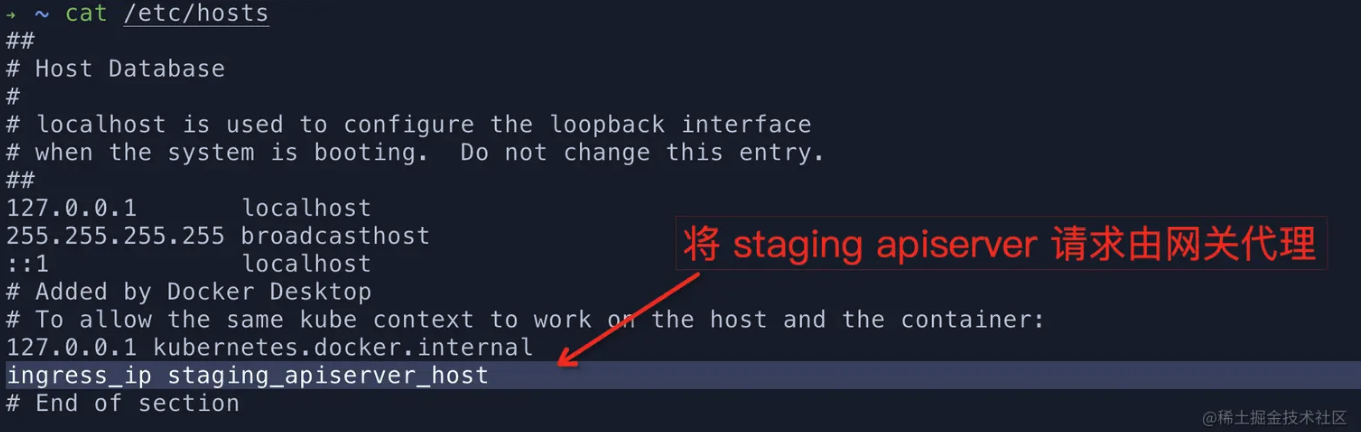
2. 修改本地 dns, 将流量打向网关
此时在 /etc/hosts 中将 staging 集群 apiserver 请求定向指向该 ingressgateway 实例
3. 本地启动脚本模拟 watch 请求
在本地启动以下脚本 watch staging pod 事件
1 | package main |
启动脚本开始 watch pod, 观察到此时 watch pod 正常.

此时登录 ingressgateway 容器观察到网关一共有2个与 apiserver 的连接(这儿看到的 8080 端口是因为开了 istio sidecar)

此时对其中一个 apiserver 实例注入丢包规则,模拟 ingress -> apiserver 请求失败。(另一台 apiserver 正常)
1 | iptables -A OUTPUT -p tcp --dst apiserver_ip_1 --dport 8080 -j DROP |
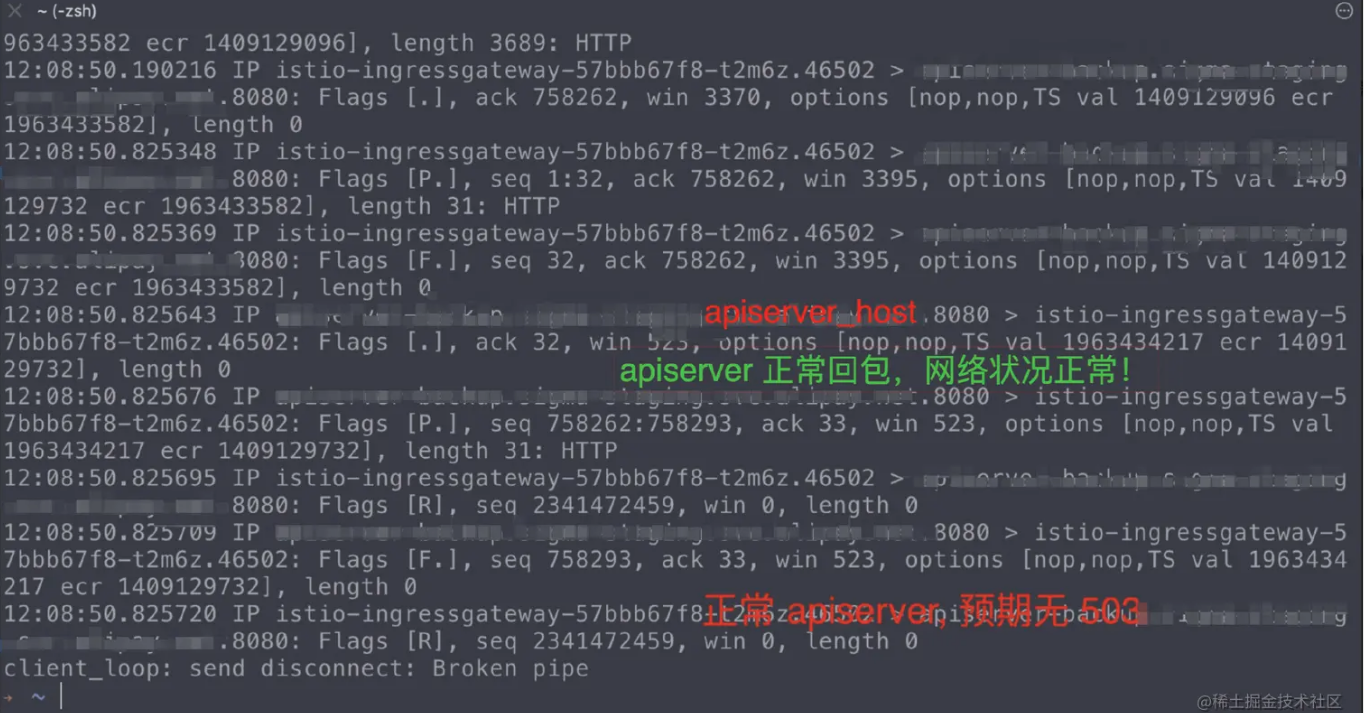
并且在网关侧同时对所有 apiserver 实例 8080 端口进行 tcpdump 抓包,预期情况下,apisever1 将不再出现新请求,同时另一个可用的 apiserver2 应该收到请求。
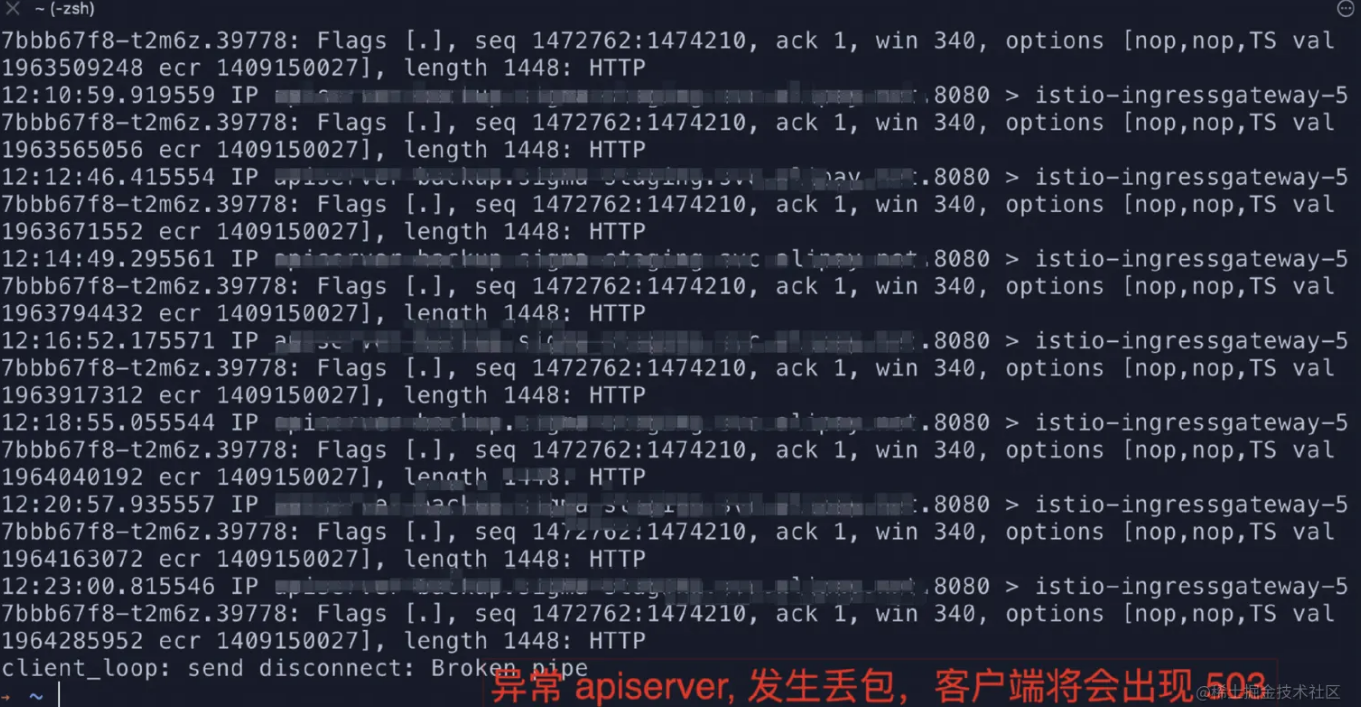
此时观察到客户端 watch 请求 Hang 住,同时出现了 503, 复现了故障期间 watch 请求不断开的场景。
排查
此时根据上述现场深挖信息,发现正常的 apiserver 抓包看到并没有收到新请求,同时异常的 apiserver 处于丢包状态无法处理请求,即从网关侧连接后端2个 apiserver 均”异常”了, 故客户端 watch 请求必然出现异常。
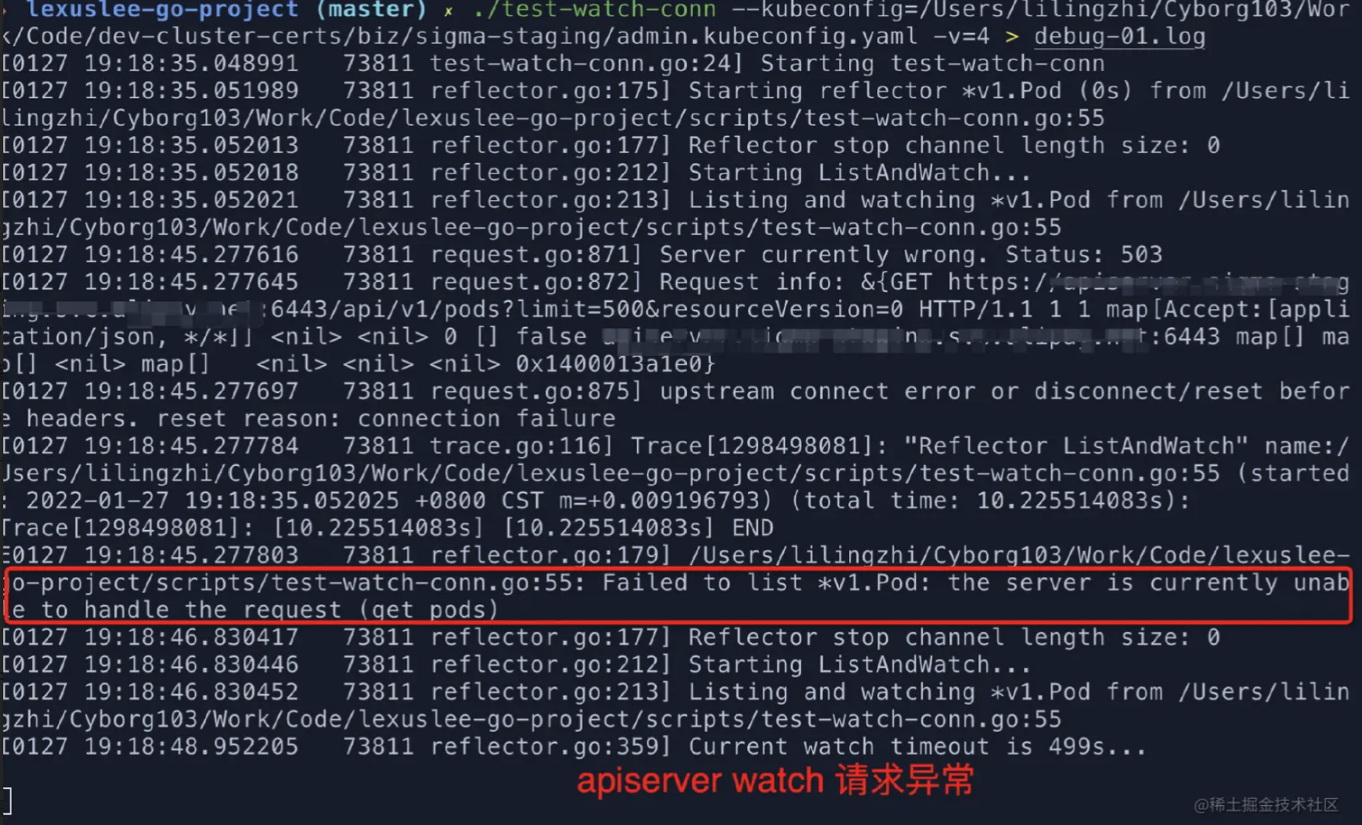
此时观察到本地客户端的 4 层 tcp 连接如下 (src port: 49739), 端口未改变过,说明客户端 -> ingress 的 tcp 连接未断开过。

于是我怀疑请求仍然走的老连接打到了异常 apiserver 上,网关侧没有做切换,将访问 apiserver 的请求路由到未丢包的 apiserver 上
找解决方案
根据上述疑点,我发现网关访问新的 apiserver 仍然是能通的,只是客户端 watch 请在于网关未断开的情况下仍使用了老的 apiserver 的连接,没有使用到这根新连接上。
于是解决方案的思路大致为:如何让客户端断开异常的 apiserver 连接并连上新的 apiserver 。
由于在我们的链路下,客户端不直接和 apiserver 通讯,而是由网关进行代理,故问题转移到了如何在网关上找到方式通知客户端进行重连。调研后得到以下两种方案:
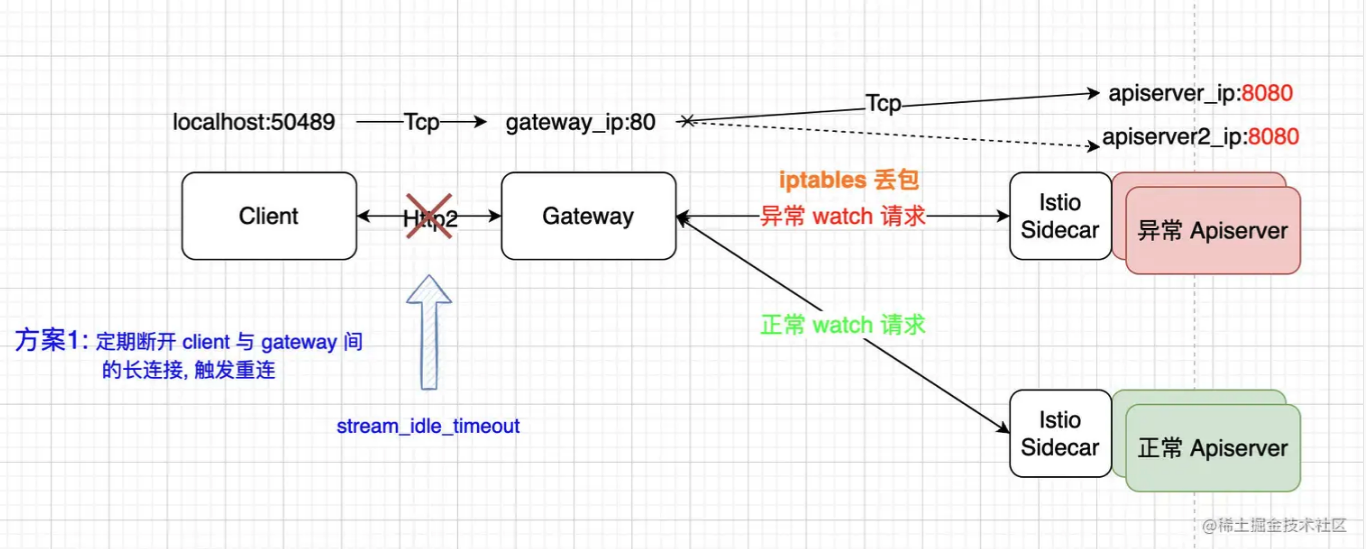
- 方案1:在网关侧配置
stream_idle_timeout参数, 由于客户端与网关在该异常下长时间没有 http2 的包传输,故必然不会有 h2 stream,那么使用该参数来使得网关侧主动断开没有包传输的老连接,触发客户端重连新连接。
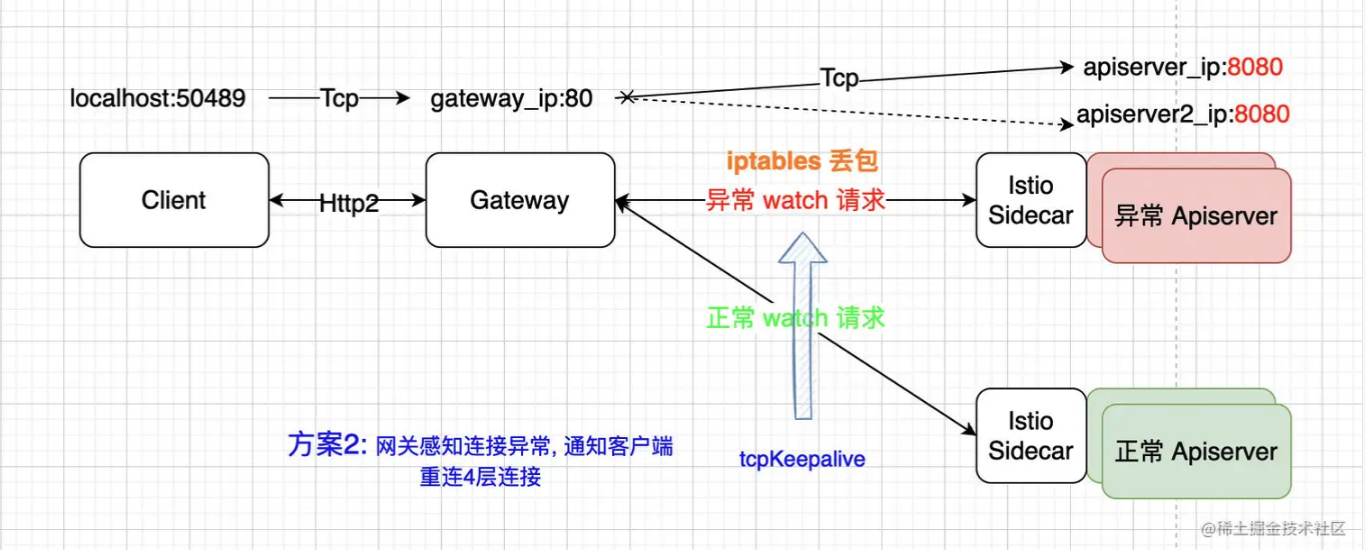
- 方案2:网关侧通过 tcpKeepalive 掐断与异常 apiserver(配置了丢包规则) 连接,使得客户端重连。
验证
我首先验证了方案1 —- stream_idle_timeout 的方式,增加如下 envoyFilter 配置。
1 | apiVersion: networking.istio.io/v1alpha3 |
网关确实能掐掉异常连接了,但也会掐掉 exec 这类客户端登录容器的”正常连接”,即业务方存在需要通过和 apiserver 建立 exec 长连接且长时间不会发送数据包的情况。加上 stream_idle_timeout 会误掐掉这些连接,对业务是有损的,于是放弃了方案一。
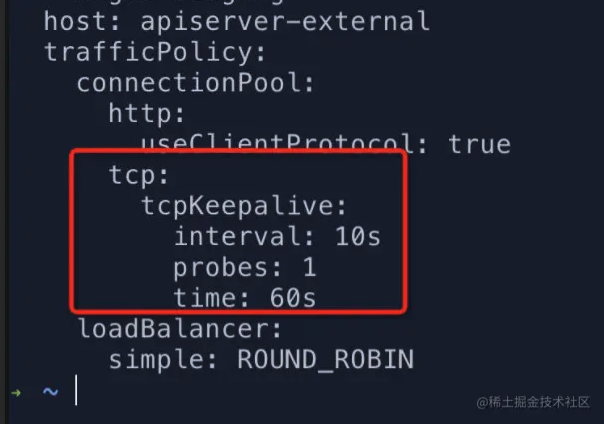
接着我开始验证方案2,修改 apiserver destinationRule 配置,增加 tcpKeepalive
接着按照丢包的方案重新启动本地测试 client 进行验证
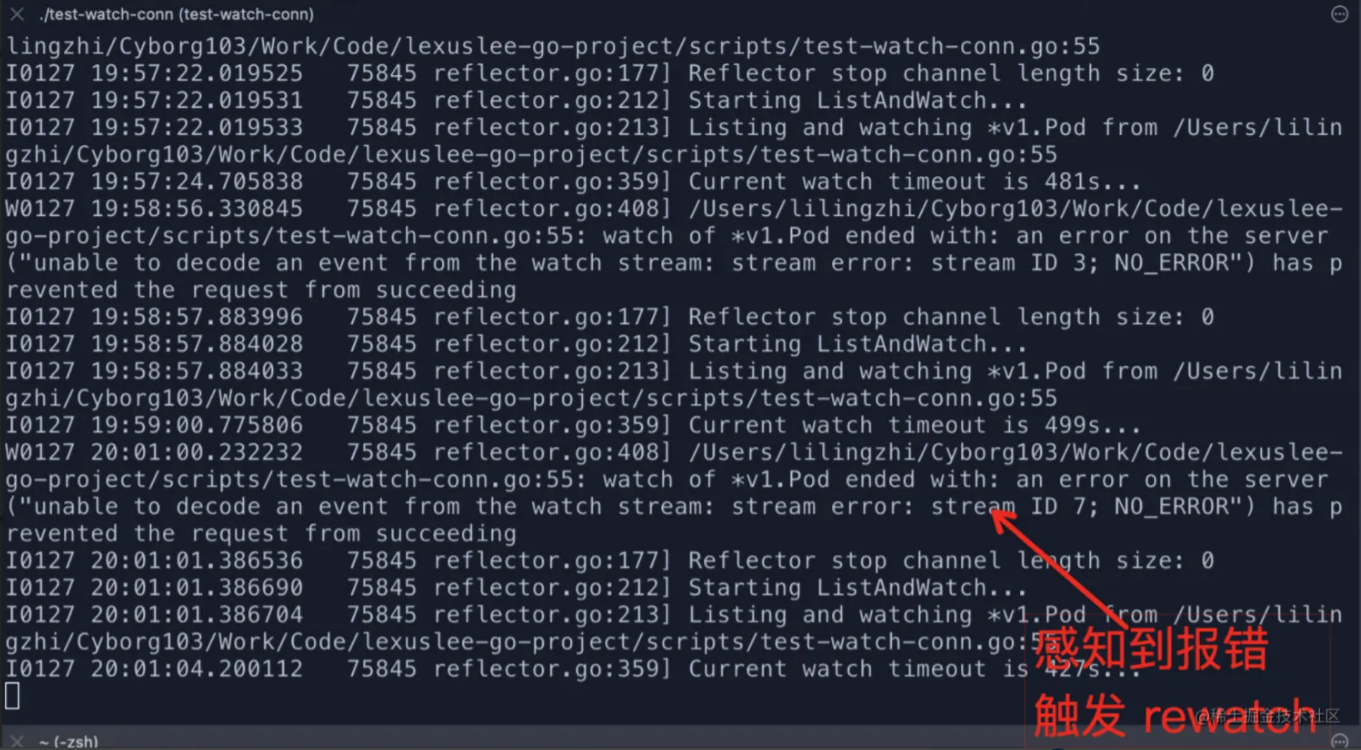
观察发现客户端在下一次 relist(ListAndWatch) 后恢复正常
同时再次在本地查看客户端端口为 49739, 4 层 tcp 连接未断开,说明客户端 -> ingress 链路正常.

进一步佐证了问题可能是 ingress 连上了不可用的 apiserver,而加上 tcpKeepalive 则让网关检查到 apiserver 不可用(仅网络层),从而切换到另一个可用的 apiserver 实例。
根据 pprof 进行结论的二次验证
由于目前所使用的 client-go 代码中增加了 watchTimeout 的逻辑,会周期性地进行 relist&watch, 从而保障 watch 请求不会长时间 hang 住

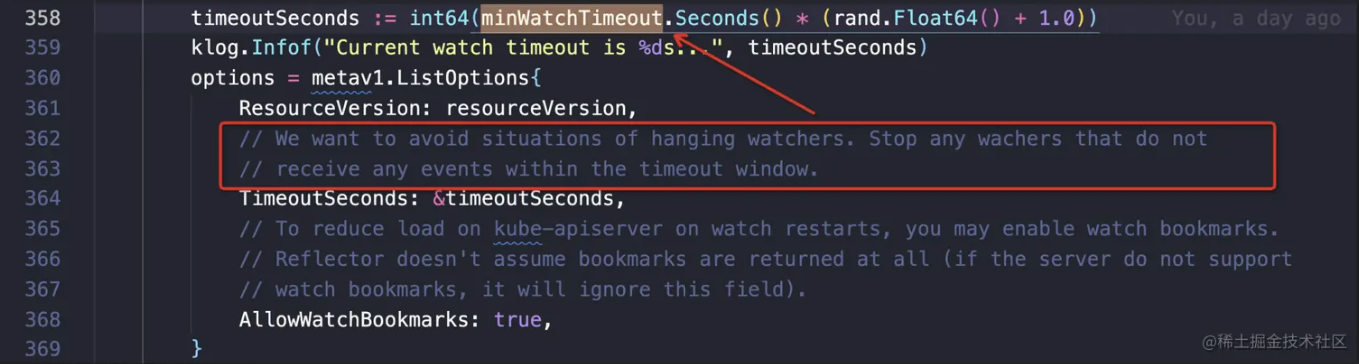
故正常情况下 client-go watch 请求行为如下:
- 预期: 在每次调用
ListAndWatch的时间窗口(5-10分钟内)未接收到请求,则会自动断开,进行 relist
在未开启 tcpKeepalive 前,出现了 watchHandler goroutine hang 住问题, 观察下图 pprof 中 goroutine stack 发现,watchHandler 这个 goroutine 运行了超过 10min,未触发 client-go 中 relist 逻辑, 不符合预期。属于 watch hang 住行为。
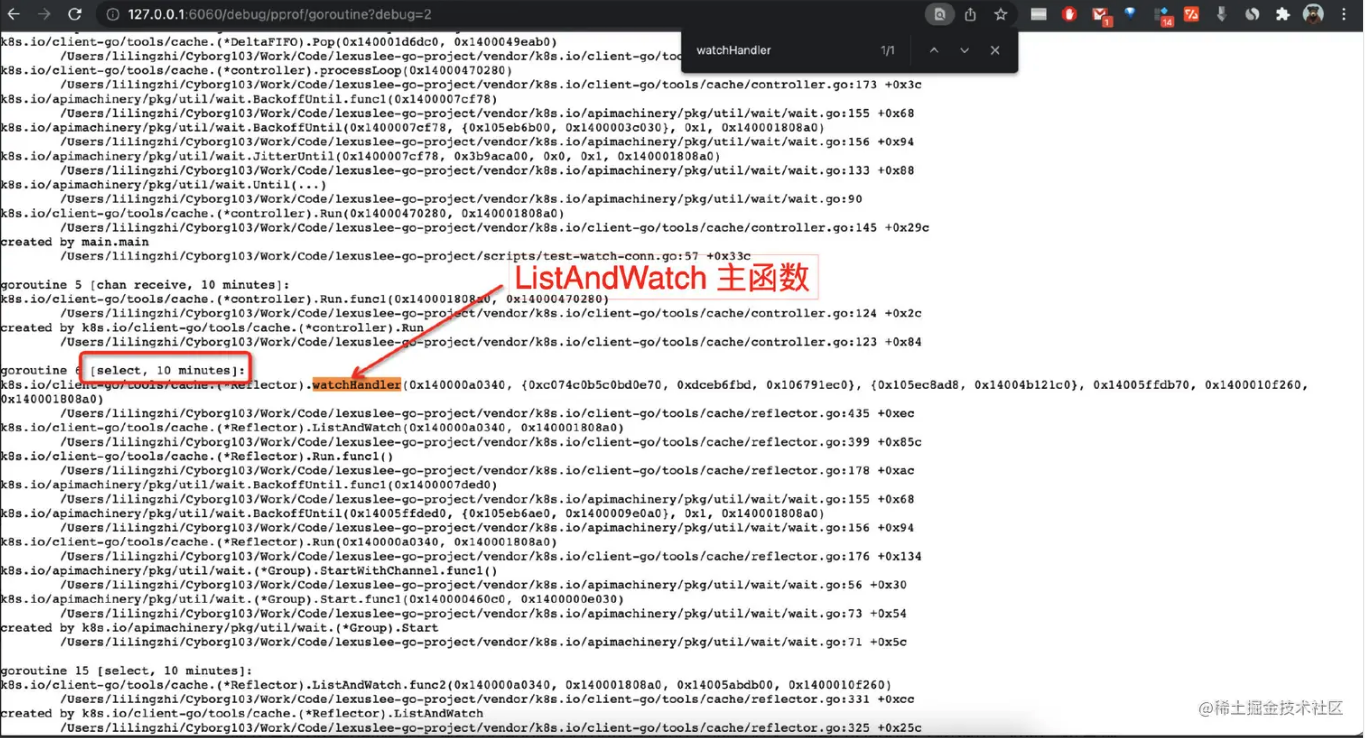
而开启 tcpKeepalive 后,watchHandler goroutine hang 住问题消失,watchHandler 均不超过 5min,符合预期。watch hang 住问题消失。
问题根因
定位到了 tcpKeepalive 能解这个问题后,咱开始怀疑这个参数的底层逻辑是啥,为啥能解这个问题。
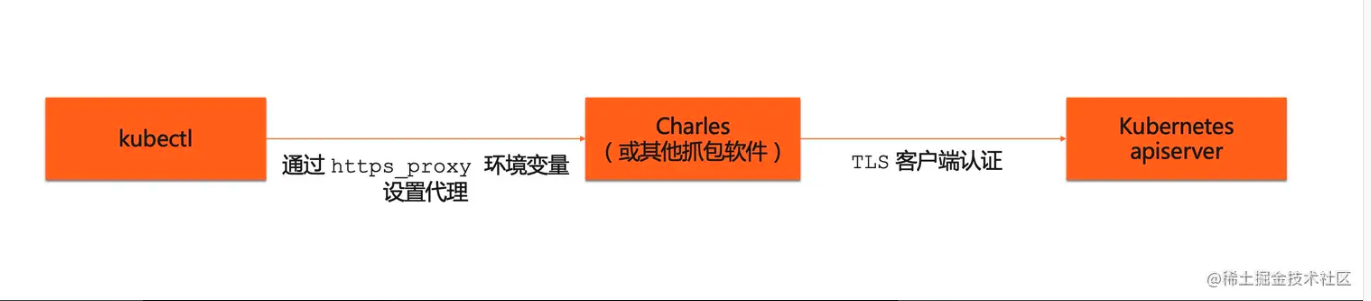
由于这个参数是作用在网络 4 层,于是我第一想法是进行抓包拿更多信息。参考上图的抓包链路,我启动了 charles 进行 k8s apiserver https 抓包。
观察发现未开启 tcpKeepalive 时,异常时(ingress 侧开启了单台 apiserver 丢包) ,客户端的 watch 请求 Tcp/Http 连接均不断开。而开启 tcpKeepalive 后,当网关访问到配置了丢包规则的 apiserver 时出现了 503, 并返回错误给客户端, 同时客户端的7层连接进行重建(streamId 变了),重建后下一次 ListAndWatch 请求可以正常拿到响应。
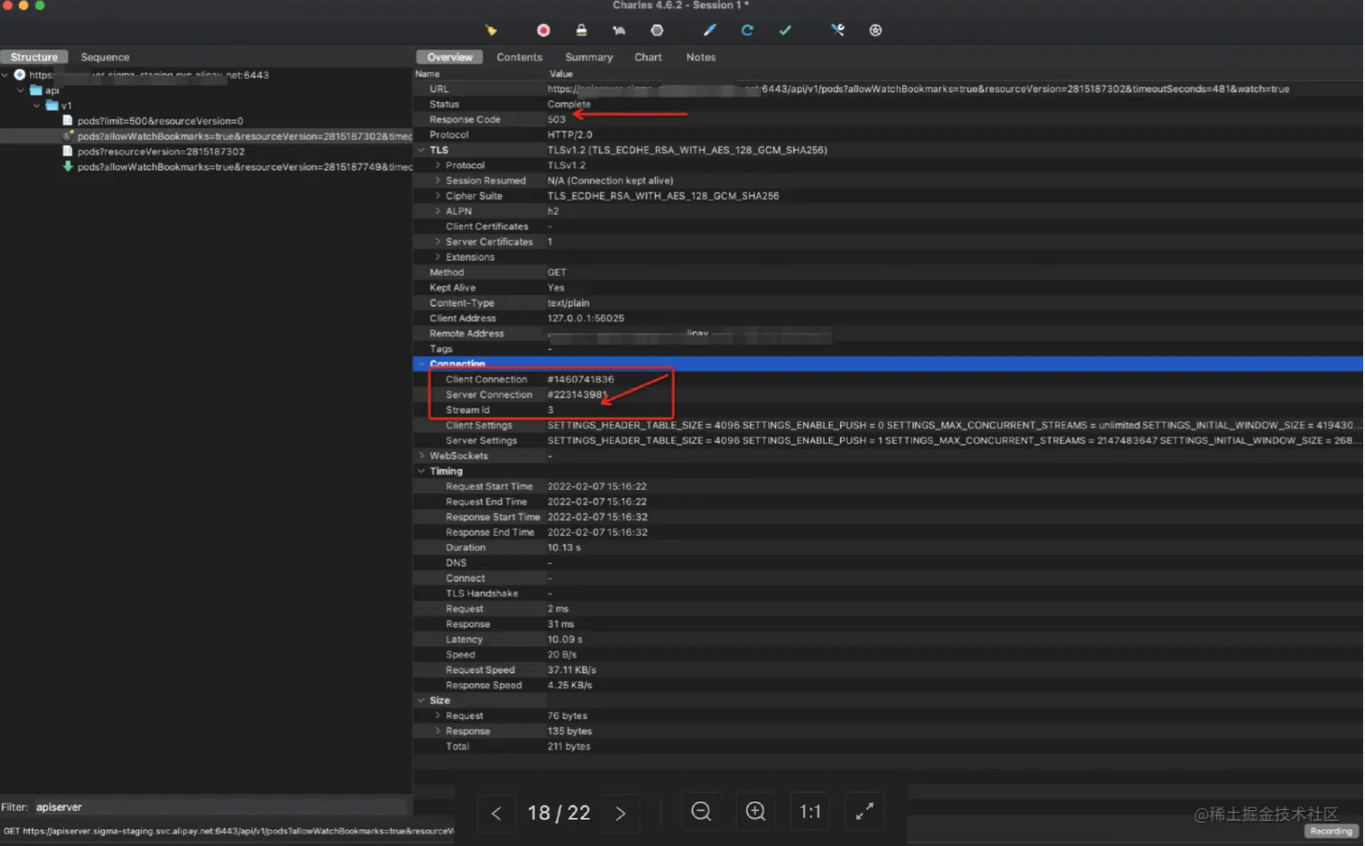
所以是什么导致了这个行为呢?
由于 charles 只能抓取 7 层的数据包,我想看看 4 层的网络行为,依葫芦画瓢,再次通过 wireshark 抓包
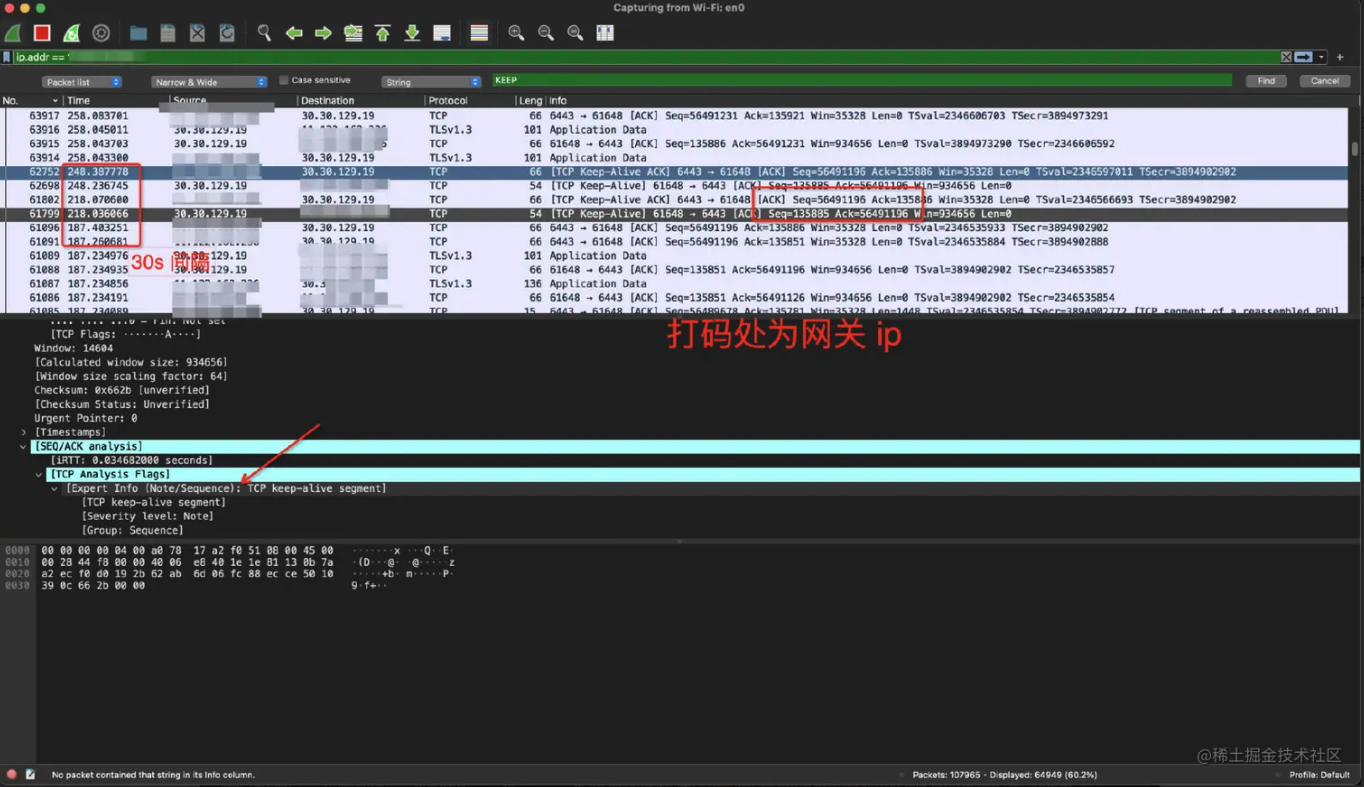
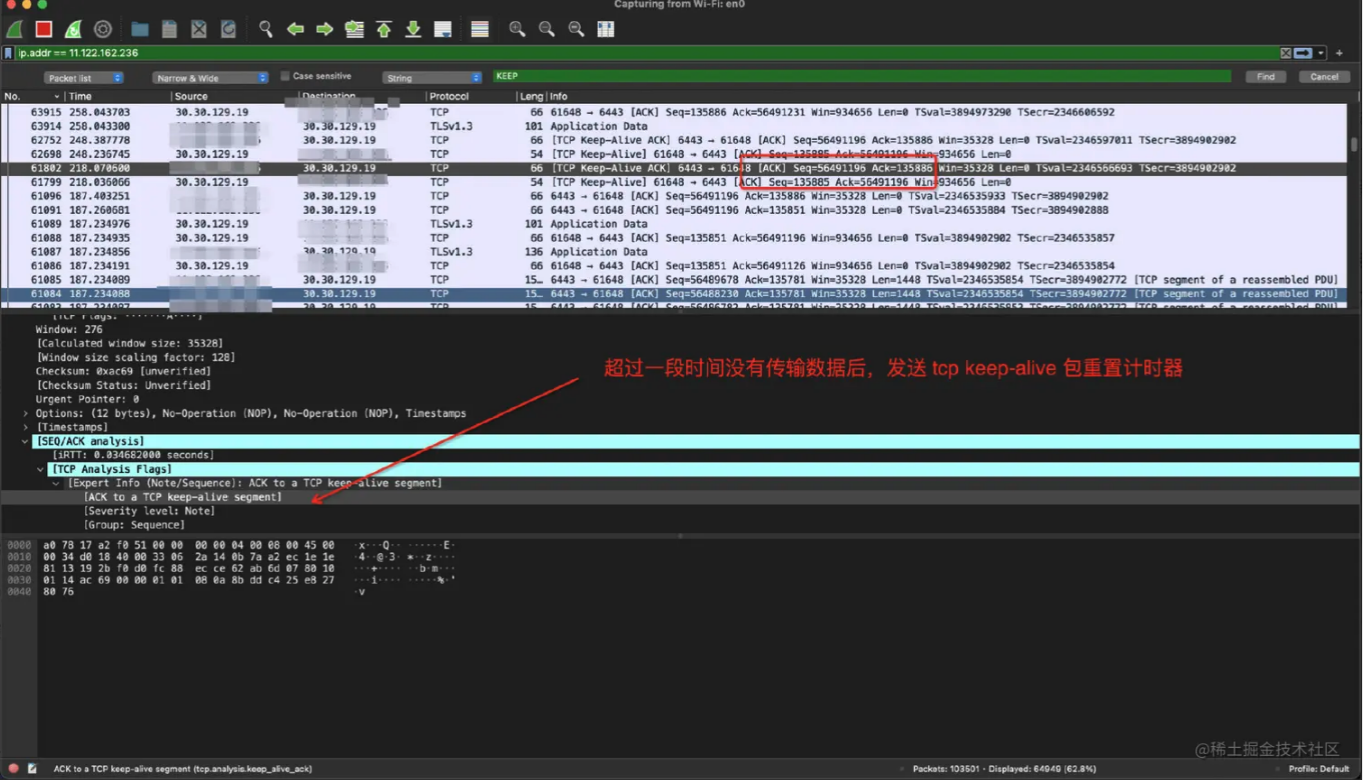
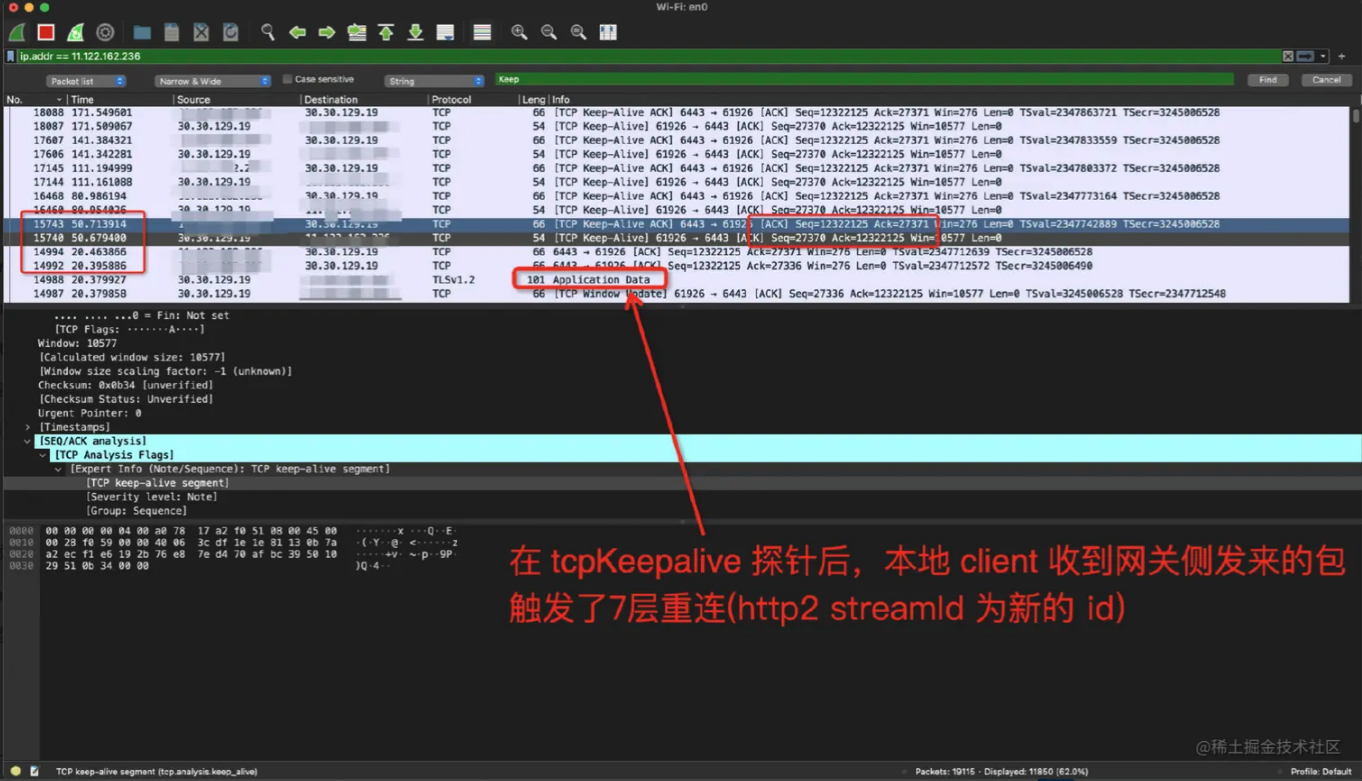
发现在开启网关侧 tcpKeepalive 后,网关侧访问异常 apiserver 失败,在网关节点上掐断了与异常 apiserver 的,同时客户端在与网关的 60s tcpkeepalive timeout 后,网关侧主动向客户端发送了一条报文,触发了客户端重建7层连接,客户端在连接重建后恢复正常,观察发现请求打到了另外一台正常的 apiserver 上。
思考
client-go 中的 watchTimeout 是依靠 apiserver 主动发起才能进行 relist,在上述丢包场景下,apiserver 无法回包,故 watch 连接 hang 住的问题在 client-go 自身的机制是无法保证能自愈的,故在整条 apiserver 访问连上上,需要加上健康检查/探活逻辑(如 istio ingressgateway 对 apiserver 的探活),才能保证 watch 请求可靠性。
