进程切换原理
什么是CPU上下文
Linux是一个多任务操作系统,它支持远大于CPU核心数的任务同时进行。当然,这些任务并不是真的同时在运行,而是因为系统在很短的时间内,将CPU轮流分配给它们,造成多任务同时运行的错觉。每个任务在运行前,CPU都需要知道任务从哪来加载,又从哪里开始运行,也就是说,需要事先帮它们设置好CPU寄存器和程序计数器( Program Counter,PC )。
CPU寄存器:是CPU内置的容量小、但速度快的内存,用来临时存放指令执行运行过程中的操作数和中间(最终)的操作结果。
程序计数器:是用来存储CPU正在运行的指令位置、或者即将执行的下一条指令位置。
CPU寄存器和程序计数器是CPU运行任何任务前,必须依赖的环境,也被称作CPU上下文。
什么是CPU上下文切换
把前一个任务的CPU上下文(CPU寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新的任务。而这些保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来。这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
CPU的上下文切换可以分为几个不同的场景:进程上下文切换、线程上线文切换、中断上下文切换;
进程上下文切换
进程的堆栈
内核在创建进程的时候,在创建task_struct的同时,会为进程创建相应的堆栈。每个进程会有两个栈,一个用户栈,存在于用户空间;一个内核栈,存在于内核空间。当进程在用户空间运行时,cpu堆栈指针寄存器里面的内容是用户堆栈地址,使用用户栈;当进程在内核空间时,cpu堆栈指针寄存器里面的内容是内核栈空间地址,使用内核栈。
系统调用时的切换
Linux按照特权等级,把进程的运行空间分为内核空间和用户空间。一些特殊的操作如调用open()打开文件等 都需要切换到内核空间运行,用户空间是没有权限调用这些的。也就是说,进程既可以在用户空间运行,又可以在内核空间运行。在用户空间运行即为用户态,而陷入内核空间的时候,即为内核态。这种从用户态切换到内核态时,必须经过系统调用来完成。
系统调用需要上下文切换。切换时,先保存CPU寄存器里原来用户态的指令位置。接着,为了执行内核态代码,CPU寄存器需要更新为内核态执行的新位置。最后才是跳转到内核态运行内核任务。系统调用结束后,CPU寄存器需要恢复原来保存的用户态,然后再切换到用户空间,继续运行进程。所以一次系统调用的过程,其实是发生了两次CPU上下文切换。
需要注意的是,系统调用过程中,并不会涉及到虚拟内存等进程用户态的资源,也不会进行切换进程。这跟我们通常说的进程上下文切换是不一样的。
所以,系统调用过程通常称为特权模式切换,而不是上下文切换。但实际上,系统调用过程中,CPU的上下文切换还是无法避免的。
进程的切换
进程是由内核来管理和调度的,进程的切换只能发生在内核态。所以,进程的上下文不仅包括虚拟内存、栈、全局变量等用户空间的资源,还包括内核堆栈、寄存器等内核空间的状态。因此,进程的上下文切换就比系统调用时多了一步:在保存当前进程的内核状态和CPU寄存器之前,需要先把该进程的虚拟内存、栈等保存下来;而加载了下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈。
当进程因为中断或者系统调用而陷入内核态之行时,进程所使用的堆栈也要从用户栈转到内核栈。
进程陷入内核态后,先把用户态堆栈的地址保存在内核栈之中,然后设置堆栈指针寄存器的内容为内核栈的地址,这样就完成了用户栈向内核栈的转换;当进程从内核态恢复到用户态之行时,在内核态之行的最后将保存在内核栈里面的用户栈的地址恢复到堆栈指针寄存器即可。这样就实现了内核栈和用户栈的互转。
那么,我们知道从内核转到用户态时用户栈的地址是在陷入内核的时候保存在内核栈里面的,但是在陷入内核的时候,我们是如何知道内核栈的地址的呢?
关键在进程从用户态转到内核态的时候,进程的内核栈总是空的。这是因为,当进程在用户态运行时,使用的是用户栈,当进程陷入到内核态时,内核栈保存进程在内核态运行的相关信息,但是一旦进程返回到用户态后,内核栈中保存的信息无效,会全部恢复,因此每次进程从用户态陷入内核的时候得到的内核栈都是空的。所以在进程陷入内核的时候,直接把内核栈的栈顶地址给堆栈指针寄存器就可以了。
发生进程上下文切换的场景:
- 为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。这样,当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待 CPU 的进程运行。
- 进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行。
- 当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度。
- 当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行
- 发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序。
进程切换的视图:
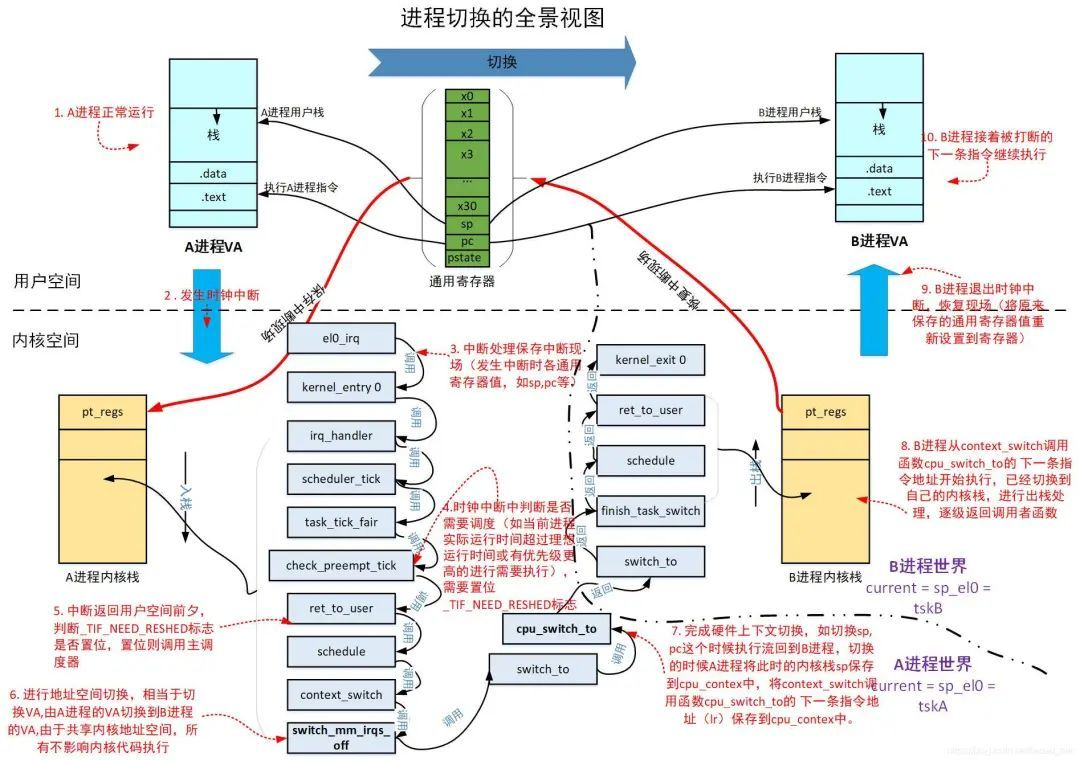
关键点:
- 发生中断时的保存现场,将发生中断时的所有通用寄存器保存到进程的内核栈,使用struct pt_regs结构。
- 地址空间切换将进程自己的页全局目录的基地址pgd保存在ttbr0_le1中,用于mmu的页表遍历的起始点。
- 硬件上下文切换的时候,将此时的调用保存寄存器和pc, sp保存到struct cpu_context结构中。做好了这几个保存工作,当进程再次被调度回来的时候,通过cpu_context中保存的pc回到了cpu_switch_to的下一条指令继续执行,而由于cpu_context中保存的sp导致当前进程回到自己的内核栈,经过一系列的内核栈的出栈处理,最后将原来保存在pt_regs中的通用寄存器的值恢复到了通用寄存器,这样进程回到用户空间就可以继续沿着被中断打断的下一条指令开始执行,用户栈也回到了被打断之前的位置,而进程访问的指令数据做地址转化(VA到PA)也都是从自己的pgd开始进行,一切对用户来说就好像没有发生一样。
总结
进程切换有两大步骤:地址空间切换和处理器状态切换(硬件上下文切换)。前者保证了进程回到用户空间之后能够访问到自己的指令和数据(其中包括减小tlb清空的ASID机制),后者保证了进程内核栈和执行流的切换,会将当前进程的硬件上下文保存在进程所管理的一块内存,然后将即将执行的进程的硬件上下文从内存中恢复到寄存器,有了这两步的切换过程保证了进程运行的有条不紊,当然切换的过程是在内核空间完成,这对于进程来说是透明的。
