Golang内存分配源码解析
- 1. Golang内存分配整体架构
- 2. makeslice
- 3. 内存初始化-mallocinit
- 3.1. mcentral初始化:
- 3.2. mallocgc-内存申请
- 3.3. 什么是内存对齐?
- 3.4. runtime.nextFreeFast-尝试从缓存中快速分配
- 3.5. mcache.nextFree-申请新的span
- 3.6. mcache.refill-向mcentral申请内存
- 3.7. mcentral.cacheSpan-向mcentral申请span
- 3.8. mcentral.grow-向heap申请内存
- 3.9. mcache.allocLarge-大对象分配
- 3.10. mheap分配流程
- 3.11. allocSpan
- 3.12. grow-向操作系统申请内存
- 3.13. sysAlloc
- 3.14. sysReserve-mmap系统调用
Golang内存分配整体架构
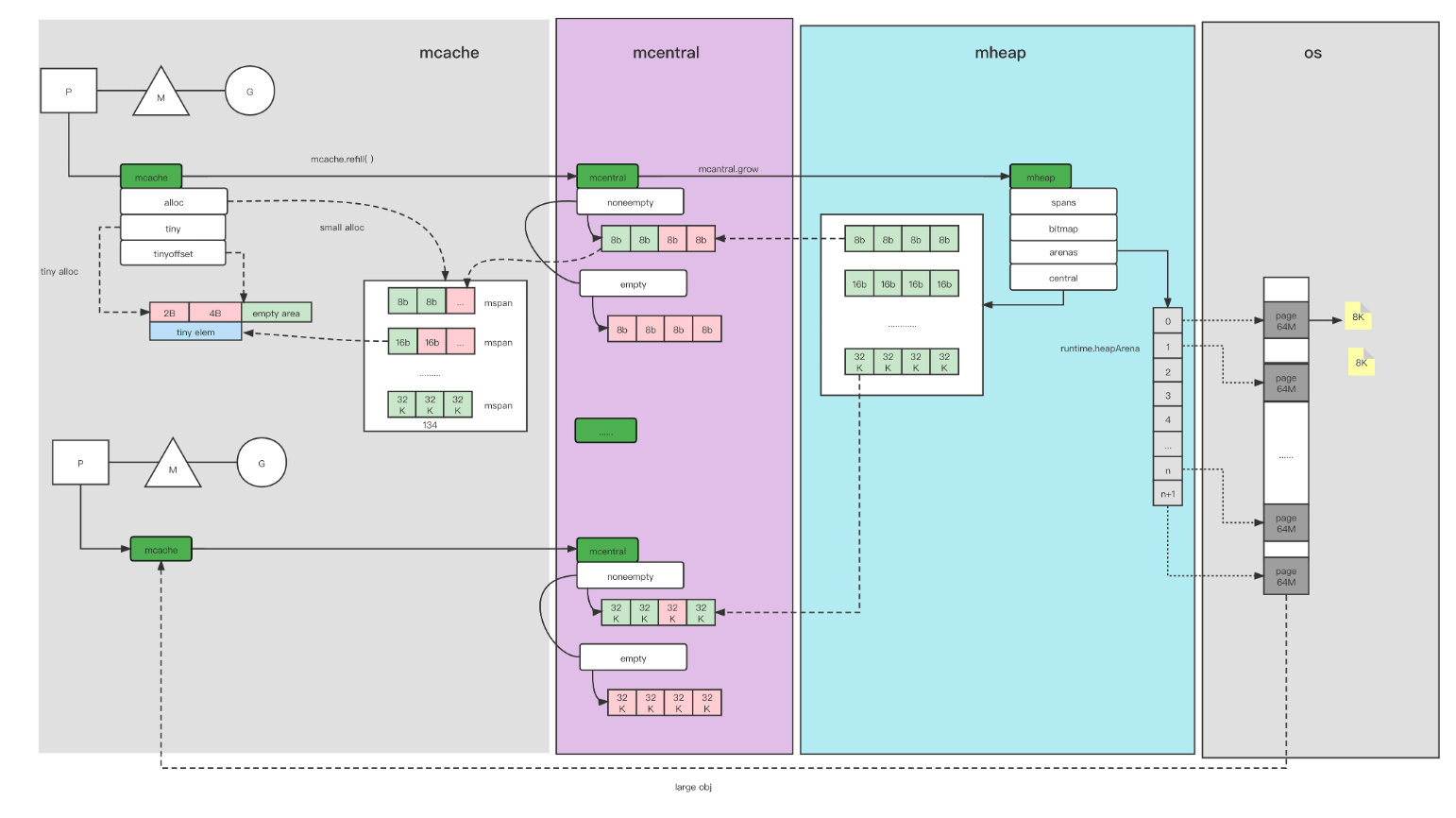
简化后:
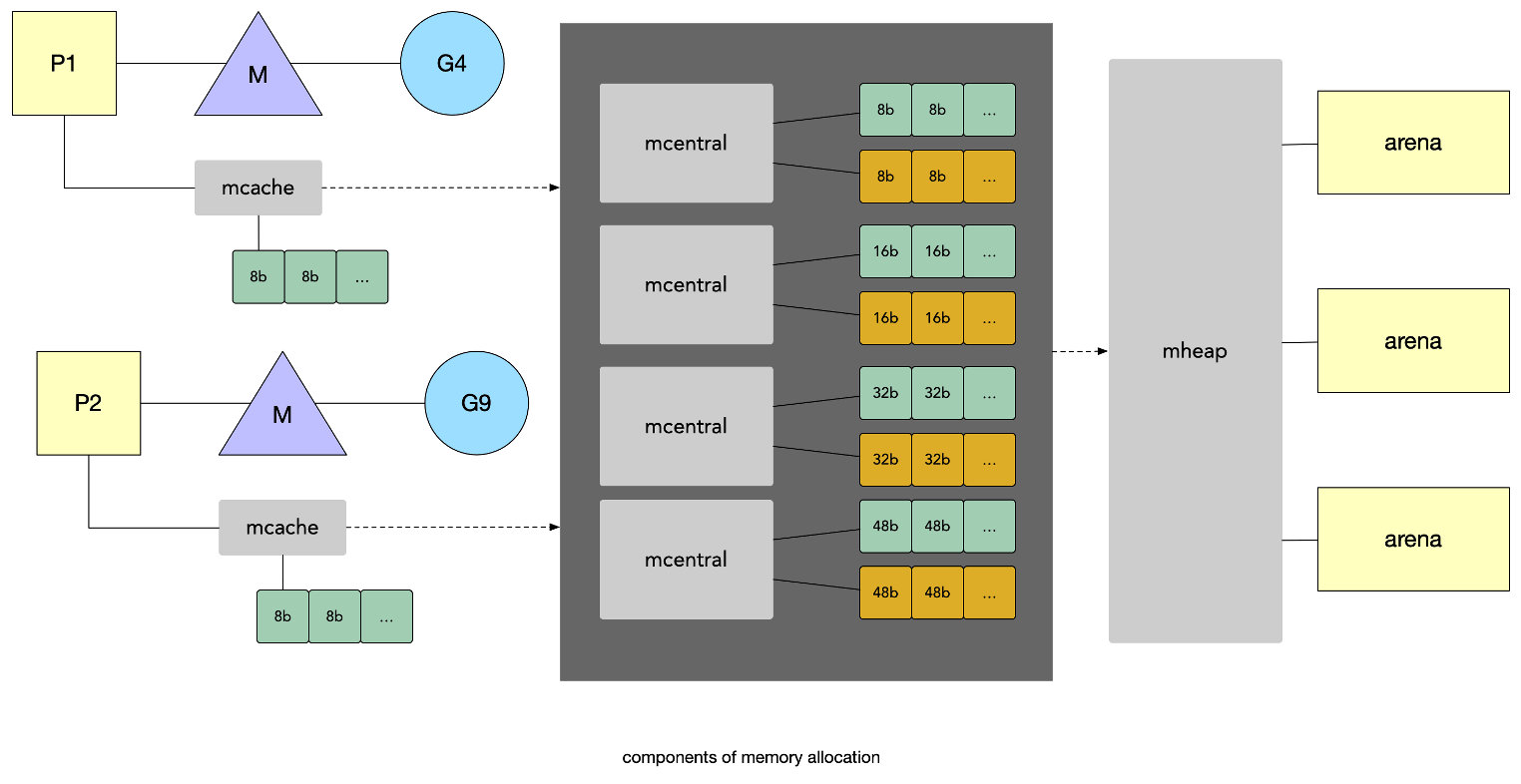
makeslice
以创建切片为例,在64位操作系统上,会调用makeslice64(),最终都会去调用makeslice()去进行最终的创建动作,先计算是否内存溢出或越界,再通过调用mallocgc分配内存给slice,源码在 runtime/slice.go
1 | func makeslice(et *_type, len, cap int) unsafe.Pointer { |
内存初始化-mallocinit
- 检查系统/硬件信息
- 计算预留空间大小
- 尝试预留地址
- 初始化mheap中的一部分变量
- 其他部分初始化,67个mcentral在这里初始化
mcentral初始化:
- 设置自己的级别
- 将两个mspanList初始化
1 | func mallocinit() { |
mcache的初始化在func procresize(nprocs int32)中,procresize也在schedinit()中调用,顺序在mallocinit()之后,所以说也就是说mcentral先初始化,然后是mcache,它在初始化P的时候初始化具体代码如下:
1 | func allocmcache() *mcache { |
这个初始化后,管理结构、mheap、67个mcentral及每个goroutine的mcache都初始化完毕。接下来就是使用时,如何分配和管理内存。
mallocgc-内存申请
/runtime/malloc.go
1 | // Allocate an object of size bytes. |
什么是内存对齐?
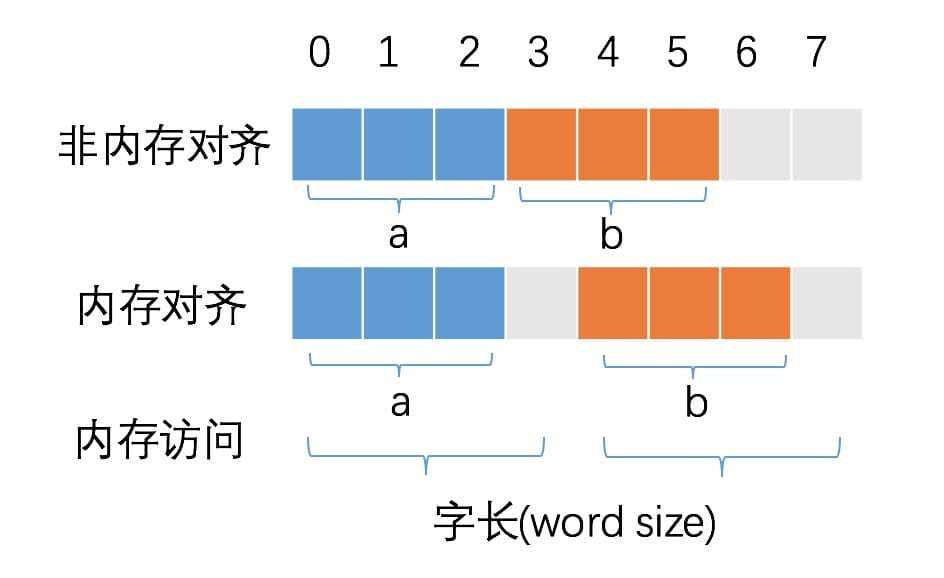
变量 a、b 各占据 3 字节的空间,内存对齐后,a、b 占据 4 字节空间,CPU 读取 b 变量的值只需要进行一次内存访问。如果不进行内存对齐,CPU 读取 b 变量的值需要进行 2 次内存访问。第一次访问得到 b 变量的第 1 个字节,第二次访问得到 b 变量的后两个字节。如果不进行内存对齐,很可能增加 CPU 访问内存的次数。
runtime.nextFreeFast-尝试从缓存中快速分配
1 | // nextFreeFast returns the next free object if one is quickly available. |
mcache.nextFree-申请新的span
如果在freeindex后无法快速找到未分配的元素, 就需要调用nextFree :
1 | // nextFree returns the next free object from the cached span if one is available. |
mcache.refill-向mcentral申请内存
如果mcache中指定类型的span已满, 就需要调用refill函数申请新的span:
1 | // refill acquires a new span of span class spc for c. This span will |
mcentral.cacheSpan-向mcentral申请span
向mcentral申请一个新的span会通过cacheSpan函数:
1 | // Allocate a span to use in an mcache. |
mcentral.grow-向heap申请内存
mcentral向mheap申请一个新的span会使用grow函数:
1 | // grow allocates a new empty span from the heap and initializes it for c's size class.func (c *mcentral) grow() *mspan { // 根据mcentral的类型计算需要申请的span的大小(除以8K = 有多少页)和可以保存多少个元素 npages := uintptr(class_to_allocnpages[c.spanclass.sizeclass()]) size := uintptr(class_to_size[c.spanclass.sizeclass()]) // 向mheap申请一个新的span, 以页(8K)为单位 s := mheap_.alloc(npages, c.spanclass, true) if s == nil { return nil } // Use division by multiplication and shifts to quickly compute: // n := (npages << _PageShift) / size n := (npages << _PageShift) >> s.divShift * uintptr(s.divMul) >> s.divShift2 s.limit = s.base() + size*n // 更新limit heapBitsForAddr(s.base()).initSpan(s) // 分配并初始化span的allocBits和gcmarkBits return s} |
mcache.allocLarge-大对象分配
对于大对象的分配allocLarge,直接回向mheap申请,同mheap_.alloc
1 | // allocLarge allocates a span for a large object.func (c *mcache) allocLarge(size uintptr, needzero bool, noscan bool) *mspan { if size+_PageSize < size { throw("out of memory") } npages := size >> _PageShift if size&_PageMask != 0 { npages++ } // Deduct credit for this span allocation and sweep if // necessary. mHeap_Alloc will also sweep npages, so this only // pays the debt down to npage pages. deductSweepCredit(npages*_PageSize, npages) spc := makeSpanClass(0, noscan) s := mheap_.alloc(npages, spc, needzero) if s == nil { throw("out of memory") } stats := memstats.heapStats.acquire() atomic.Xadduintptr(&stats.largeAlloc, npages*pageSize) atomic.Xadduintptr(&stats.largeAllocCount, 1) memstats.heapStats.release() // Update heap_live and revise pacing if needed. atomic.Xadd64(&memstats.heap_live, int64(npages*pageSize)) if trace.enabled { // Trace that a heap alloc occurred because heap_live changed. traceHeapAlloc() } if gcBlackenEnabled != 0 { gcController.revise() } // Put the large span in the mcentral swept list so that it's // visible to the background sweeper. mheap_.central[spc].mcentral.fullSwept(mheap_.sweepgen).push(s) s.limit = s.base() + size heapBitsForAddr(s.base()).initSpan(s) return s} |
mheap分配流程
alloc
1 | // alloc allocates a new span of npage pages from the GC'd heap.//// spanclass indicates the span's size class and scannability.//// If needzero is true, the memory for the returned span will be zeroed.func (h *mheap) alloc(npages uintptr, spanclass spanClass, needzero bool) *mspan { // Don't do any operations that lock the heap on the G stack. // It might trigger stack growth, and the stack growth code needs // to be able to allocate heap. var s *mspan systemstack(func() { // To prevent excessive heap growth, before allocating n pages // we need to sweep and reclaim at least n pages. if h.sweepdone == 0 { h.reclaim(npages) // 回收一部分内存 } s = h.allocSpan(npages, spanAllocHeap, spanclass) // 申请内存 }) if s != nil { if needzero && s.needzero != 0 { memclrNoHeapPointers(unsafe.Pointer(s.base()), s.npages<<_PageShift) } s.needzero = 0 } return s} |
allocSpan
1 | func (h *mheap) allocSpan(npages uintptr, typ spanAllocType, spanclass spanClass) (s *mspan) { |
grow-向操作系统申请内存
1 | // Try to add at least npage pages of memory to the heap, |
sysAlloc
grow会通过curArena的end值来判断是不是需要从系统申请内存;如果end小于nBase那么会调用runtime.mheap.sysAlloc方法从操作系统中申请更多的内存 :
1 | // sysAlloc allocates heap arena space for at least n bytes. The |
sysReserve-mmap系统调用
在Linux系统上调用mmap函数
Mmap:Mmap是内存映射文件的缩写。它是一种无需调用系统调用就能读写文件的方式。操作系统预留了程序虚拟地址的一块,直接 “映射 “到文件中的一块。因此,如果程序从该部分地址空间读取数据,就会获得驻留在文件相应部分的数据。如果文件的那部分数据恰好驻留在缓冲区缓存中,那么在第一次访问时,只需将映射后的块的虚拟地址映射到相应的缓冲区缓存页的物理地址即可,以后不会再调用系统调用或其他陷阱。如果文件数据不在缓冲区缓存中,访问映射区域会产生一个页面故障,提示内核去从磁盘中获取相应的数据
分配、释放内存在不同的平台 (linux/win/bsd) 有差异,所以 Go 先对这些基础函数进行了封装,如Linux在runtime/mem-linux.go中
1 | func sysReserve(v unsafe.Pointer, n uintptr) unsafe.Pointer { |
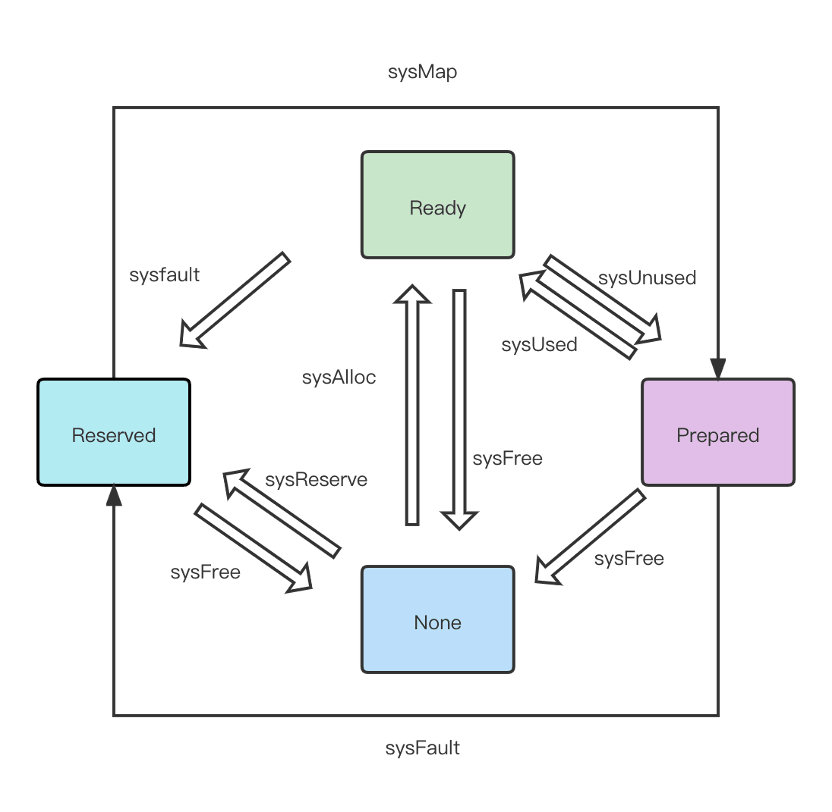
另外,runtime还提供了sysReserve,sysUnused,sysUsed,sysFree,sysFault,sysMap一系列方法,将内存在不同的下列四种状态间切换
- None:内存没有被保留或者映射,是地址空间的默认状态
- Reserve:运行时持有该地址空间,但是访问该内存会导致错误
- Prepare:内存被保留
- Ready:可以被安全访问
finish
至此,内存申请的整个流程结束。
本文引自这里
