Transformer推理性能优化技术——KVcache
Motivation: 为什么要KVCache
对于LLM类模型的一次推理(生成一个token)的过程,我们可以将这个过程分解为下列过程:

用一个流程图来表示,就是:
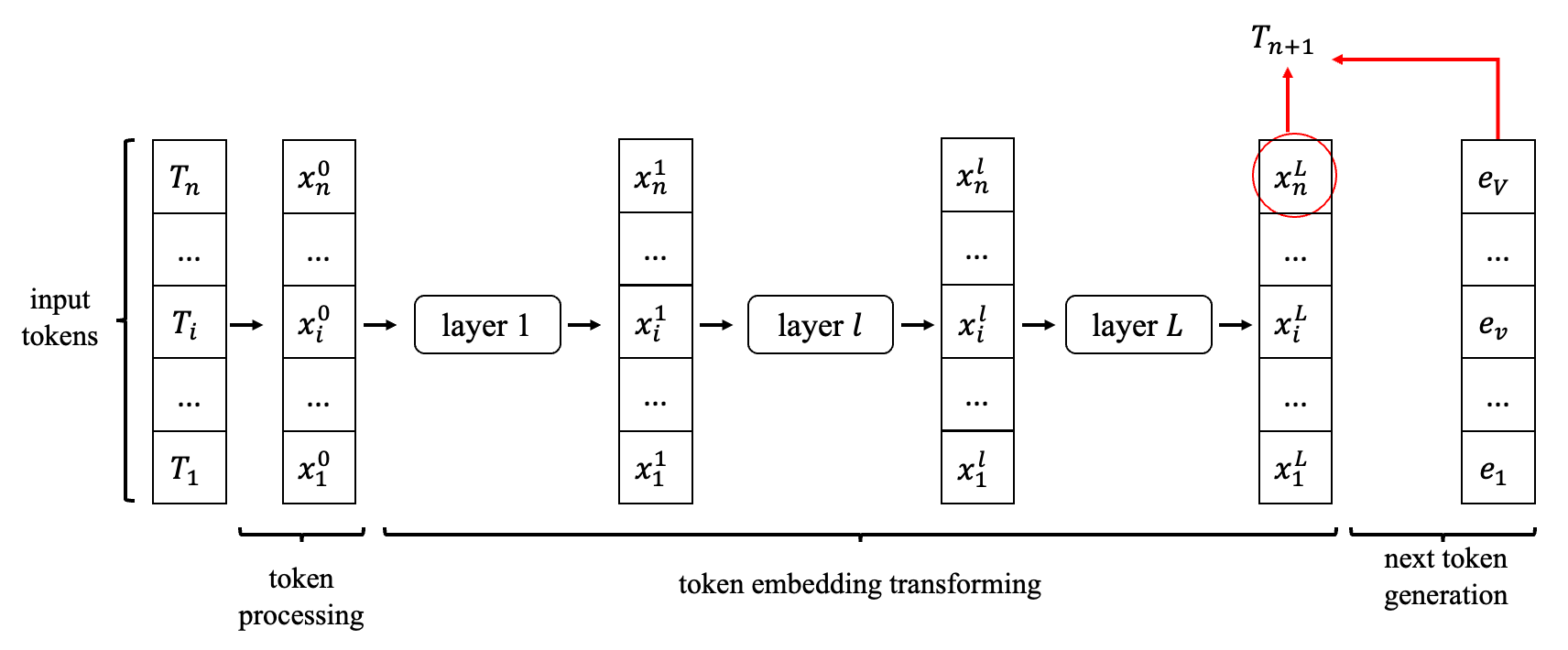
通过如下具体的代码查看详细推理逻辑:
1 | from transformers import GPT2LMHeadModel, GPT2Tokenizer |
输出结果:
1 | Embedding dimension (D): 768 |
嵌入层(Embedding Layer)的含义
嵌入层是语言模型(如GPT-2)中的一个关键组件,它将输入的每个token(通常是一个整数,代表词汇表中的某个单词或子词)映射为一个高维向量,称为token embedding。这些向量是模型处理的核心表示,用于捕捉token的语义信息。
输入:一个token(如单词“hello”在词汇表中的ID,例如整数150)。
输出:一个高维向量 $x_i^0$,维度为 $D$,通常是一个实数值向量(例如,768维或更高)。
作用:这个向量表示token在高维空间中的语义特征,不同token的向量可以通过训练学习到语义上的相似性(例如,“cat”和“dog”的向量可能在空间中较接近)。
在上述的描述中,输入序列 ${T_1, \cdots, T_i, \cdots, T_n}$ 的每个token $T_i$ 通过嵌入层被转换为对应的token embedding ${x_1^0, \cdots, x_i^0, \cdots, x_n^0}$,每个 $x_i^0$ 是一个 $D$ 维向量。
以GPT-2为例:维度 $D$ 是多少?
在GPT-2模型中,嵌入层的输出维度 $D$ 具体取决于模型的大小版本。以下是GPT-2不同版本的 $D$ 值(也称为隐藏维度或模型维度):
GPT-2 Small:$D = 768$ 维
GPT-2 Medium:$D = 1024$ 维
GPT-2 Large:$D = 1280$ 维
GPT-2 XL:$D = 1600$ 维
以最常用的 GPT-2 Small 为例,每个token通过嵌入层被映射为一个 768维的向量。这个向量 $x_i^0$ 就是初始的token embedding,进入Transformer层进行后续处理。
Token Embedding 和隐藏状态的关系
Token Embedding:指的是嵌入层直接输出的初始向量 ${x_1^0, \cdots, x_i^0, \cdots, x_n^0}$,也就是第0层的输出。这些向量是token的初始表示,尚未经过Transformer层的处理。
隐藏状态(Hidden States):在Transformer模型中,每一层的输出都可以称为隐藏状态。例如,第1层的输出是 ${x_1^1, \cdots, x_i^1, \cdots, x_n^1}$,第2层是 ${x_1^2, \cdots, x_i^2, \cdots, x_n^2}$,依此类推。隐藏状态是每一层对token embedding的进一步变换结果,维度仍然是 $D$(在GPT-2中,例如768维)。
区别:
- Token embedding 是初始输入(第0层的隐藏状态)。
- 隐藏状态是每一层Transformer的输出,是对token embedding的动态更新,包含了更多的上下文信息。
在GPT-2中,嵌入层的输出(token embedding)维度与后续Transformer层的隐藏状态维度是相同的(例如,768维)。因此,token embedding 可以看作是第0层的隐藏状态,但术语上“隐藏状态”更常指Transformer层处理后的结果。
3.1 隐藏状态的存储与计算
- 单序列的隐藏状态大小:
- 计算公式:
batch_size × seq_length × hidden_dim × layers × bytes_per_float(通常 float16 占 2 字节)。 - 例如,DeepSeek 67B(
hidden_dim=8192)处理 2K 长度序列时:- 单层隐藏状态大小:
1 × 2048 × 8192 × 2 = 32 MB。 - 64 层总大小:约 2 GB(仅隐藏状态,未计参数)。
- 单层隐藏状态大小:
- 计算公式:
- GPT-4 的更高需求:
- 若
hidden_dim=12288,处理长上下文时显存占用显著增加(需分布式计算)。
- 若
标准KV缓存计算公式
KV缓存大小:
batch_size × seq_length × layers × num_key_value_heads × head_dim × 2 × bytes_per_floatbatch_size:批量大小。
seq_length:序列长度。
layers:层数。
num_key_value_heads:键值头数。
head_dim:每个头的维度(键和值的向量维度)。
乘以 2:因为需要存储键和值。
bytes_per_float:每个元素占用的字节数。
GPT-2嵌入层的具体实现
- 嵌入矩阵:GPT-2的嵌入层是一个可学习的矩阵,大小为 $[V, D]$,其中 $V$ 是词汇表大小(对于GPT-2,$V = 50257$),$D$ 是嵌入维度(例如768)。
- 映射过程:对于输入的token ID(整数),嵌入层通过查找(lookup)或one-hot编码与嵌入矩阵相乘,得到对应的 $D$ 维向量。
- 初始化:这些向量在训练过程中通过优化(如梯度下降)学习,以捕捉token的语义信息。
例如,给定token“hello”(假设ID为150),嵌入层会输出一个768维的向量 $x_{150}^0$,这个向量随后被送入Transformer层进行处理。

我们可以用简单的代码来验证这一结论:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19import torch
from transformers import GPT2Tokenizer, GPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2Model.from_pretrained('gpt2')
# text: "The quick brown fox jumps over the lazy"
tokens = [[464, 2068, 7586, 21831, 18045, 625, 262, 16931]]
input_n = torch.tensor(tokens)
output_n = model(input_ids=input_n, output_hidden_states=True)
# text: " dog"
tokens[0].append(3290)
input_n_plus_1 = torch.tensor(tokens)
output_n_plus_1 = model(input_ids=input_n_plus_1, output_hidden_states=True)
for i, (hidden_n, hidden_n_plus_1) in enumerate(zip(output_n.hidden_states, output_n_plus_1.hidden_states)):
print(f"layer {i}, max difference {(hidden_n - hidden_n_plus_1[:, :-1, :]).abs().max().item()}")
assert torch.allclose(hidden_n, hidden_n_plus_1[:, :-1, :], atol=1e-4)输出结果:
1
2
3
4
5
6
7
8
9
10
11
12
13layer 0, max difference 0.0
layer 1, max difference 0.0
layer 2, max difference 0.0
layer 3, max difference 0.0
layer 4, max difference 0.0
layer 5, max difference 0.0
layer 6, max difference 0.0
layer 7, max difference 0.0
layer 8, max difference 0.0
layer 9, max difference 0.0
layer 10, max difference 0.0
layer 11, max difference 0.0
layer 12, max difference 0.0
更具体的计算流程如下图所示:
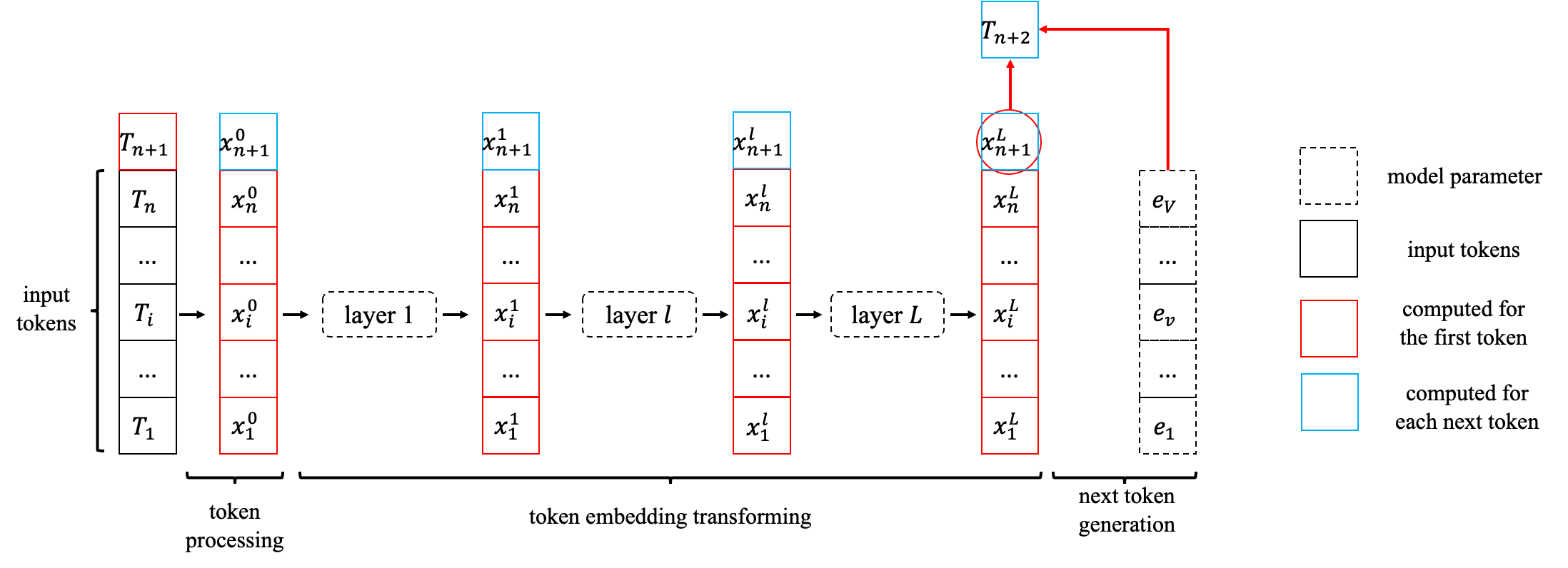
我们使用不同的颜色来区分初始输入(黑色)、生成第一个token时计算得出的中间结果(红色)、后续生成每个token需要计算并保存的中间结果(蓝色)。
严格来说,本文中的nnn表示输入prompt的token数目,随着generation进行,我们还需要引入另一个变量来表示generate的token个数。为了避免引入太多符号,下文中我们用nnn表示prompt的token数目加上已经generate的token个数,也就是当前拥有的token数。这样我们就能聚焦在next token prediction本身了。
KVCache的原理及设计细节

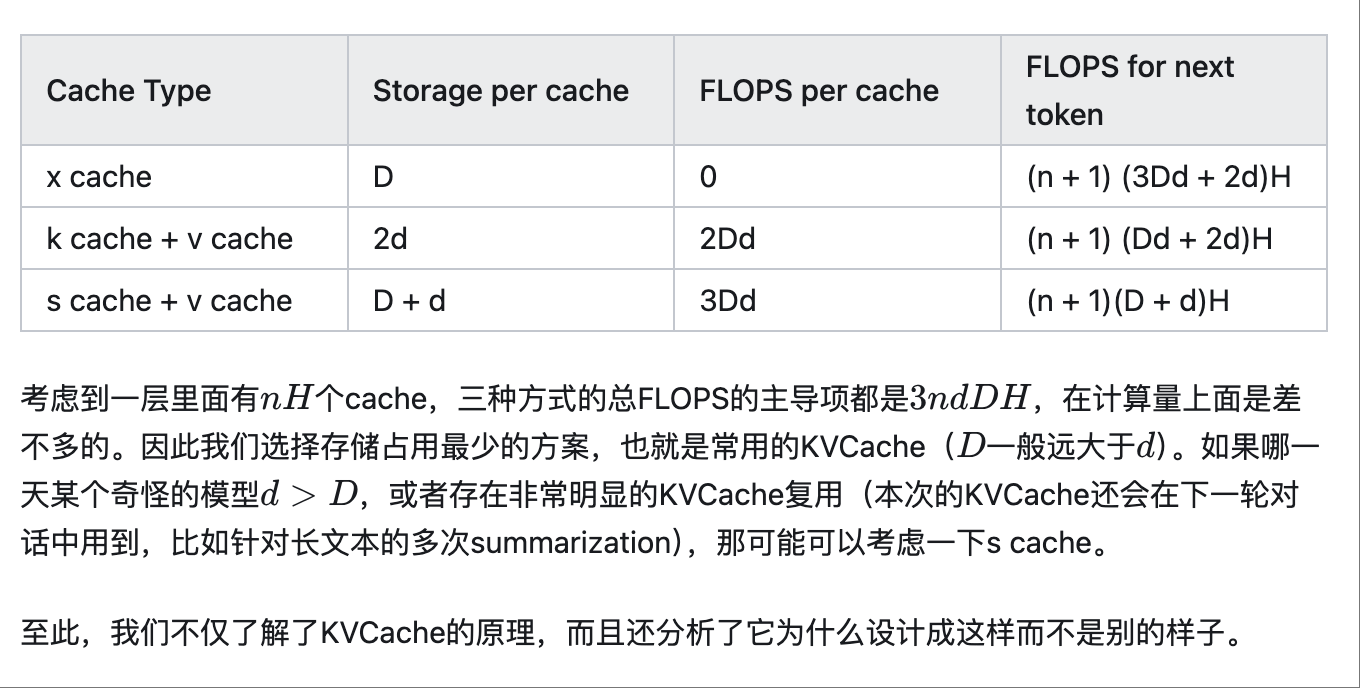
KVCache的存储及实现细节

分配一个最大容量的缓冲区,要求提前预知最大的token数量。而且现在大模型卷得厉害,动不动支持上百万长度,而大部分的用户请求都很短。因此,按照最大容量来分配是非常浪费的。
动态分配缓冲区大小,类似经典的vector append的处理方式,超过容量了就扩增一倍。这也是一种可行的解决方案,但是(在GPU设备上)频繁申请、释放内存的开销很大,效率不高。
把数据拆散,按最小单元存储,用一份元数据记录每一块数据的位置。
最后一种方案,就是目前采用最多的方案,也叫PageAttention。程序在初始化时申请一整块显存(例如4GB),按照KVCache的大小划分成一个一个的小块,并记录每个token在推理时要用到第几个小块。小块显存的申请、释放、管理,类似操作系统对物理内存的虚拟化过程,这就是大名鼎鼎的vLLM的思路(具体参见论文Efficient Memory Management for Large Language Model Serving with PagedAttention)。
KVCache成立条件
KVCache是一种用更大的显存空间换取更快的推理速度的手段。那么,它是否能够无条件适用于所有的LLM呢?其实并不是的。分析了它的原理后,我们就可以得出它适用的条件:


