Calico eBPF数据平面
什么是 eBPF
eBPF 是嵌入在 Linux 内核中的虚拟机。它允许将小程序加载到内核中,并附加到钩子上,当某些事件发生时会触发这些钩子。这允许(有时大量)定制内核的行为。虽然 eBPF 虚拟机对于每种类型的钩子都是相同的,但钩子的功能却大不相同。由于将程序加载到内核中可能很危险;内核通过非常严格的静态验证器运行所有程序;验证程序对程序进行沙箱处理,确保它只能访问允许的内存部分,并确保它必须快速终止。
eBPF 能做什么
eBPF 程序的类型
有几类钩子可以在内核中附加 eBPF 程序。eBPF 程序的功能很大程度上取决于它所附加的钩子:
跟踪程序可以附加到内核中很大一部分功能上。跟踪程序对于收集统计信息和深入调试内核很有用。 大多数跟踪挂钩只允许对函数正在处理的数据进行只读访问,但也有一些允许修改数据。例如,找出内核意外丢弃数据包的原因。
流量控制(tc) 程序可以在入口和出口处附加到给定的网络设备。内核为每个数据包执行一次程序。由于钩子用于数据包处理,内核允许程序修改或扩展数据包,丢弃数据包,将其标记为排队,或将数据包重定向到另一个接口。Calico 的 eBPF 数据平面就是基于这种类型的钩子;Calico 使用 tc 程序对 Kubernetes 服务进行负载均衡,实施网络策略,并为已建立连接的流量创建快速路径。
XDP或“eXpress 数据路径”实际上是 eBPF 挂钩的名称。每个网络设备都有一个 XDP 入口挂钩,在内核为数据包分配套接字缓冲区之前,每个传入数据包都会触发一次该挂钩。XDP 可以为 DoS 保护(在 Calico 的标准 Linux 数据平面中支持)和入口负载平衡(在 facebook 的 Katran 中使用)等用例提供出色的性能。XDP 的缺点是它需要网络设备驱动程序支持才能获得良好的性能。XDP 本身不足以实现 Kubernetes pod 网络所需的所有逻辑,但 XDP 和流量控制挂钩的组合效果很好。
套接字程序挂钩到套接字上的各种操作,例如,允许 eBPF 程序更改新创建的套接字的目标 IP,或强制套接字绑定到“正确的”源 IP 地址。Calico 使用此类程序对 Kubernetes 服务进行连接时负载均衡;这减少了开销,因为数据包在处理路径上没有做DNAT。
有各种与安全相关的钩子允许以各种方式监管程序行为。例如,seccomp挂钩允许以细粒度的方式监管系统调用。
内核通过helper functions公开每个钩子的功能。例如,tc 钩子有一个 helper function 来调整数据包的大小,但该帮助函数在跟踪钩子中不可用。使用 eBPF 的挑战之一是不同的内核版本支持不同的助手,而缺少助手可能会导致无法实现特定的功能。
BPF maps
attach 到 eBPF 挂钩的程序能够访问 BPF maps。BPF map 有两个主要用途:
允许 BPF 程序存储和检索长期存在的数据。
允许 BPF 程序和用户空间程序之间的通信。BPF 程序可以读取用户空间写入的数据,反之亦然。
有许多类型的 BPF map,包括一些允许在程序之间跳转的特殊类型,以及一些充当队列和堆栈而不是严格作为 key/value map 的类型。Calico 使用map来跟踪活动连接,并使用策略和服务 NAT 信息配置 BPF 程序。
Calico 的 eBPF 数据平面
Calico 的 eBPF 数据平面是标准 Linux 数据平面(基于 iptables)的替代方案。标准数据平面侧重于通过与 kube-proxy 和 iptables 规则进行交互来实现兼容性,而 eBPF 数据平面则侧重于性能、延迟和改善用户体验,并提供标准数据平面中无法实现的功能。作为其中的一部分,eBPF 数据平面将 kube-proxy 替换为 eBPF 实现。主要的“用户体验”功能是在流量到达 NodePort 时保留来自集群外部的流量源 IP;这使服务器端日志和网络策略在该路径上更加有用。
新的数据平面与 Calico 的标准Linux网络数据平面相比
它可以扩展到更高的吞吐量。
它每 GBit 使用更少的 CPU。
它原生支持 Kubernetes 服务(不需要 kube-proxy):
- 减少数据包到服务的第一个数据包延迟。
- 将外部客户端源 IP 地址一直保留到 pod。
- 支持 DSR(Direct Server Return),实现更高效的服务路由。
- 使用比 kube-proxy 更少的 CPU 来保持数据平面同步。
要了解更多的性能指标,请参阅博客 介绍 Calico eBPF 数据平面
限制
eBPF 模式目前相对于标准 Linux 管道模式有一些限制:
- eBPF 模式仅支持 x86-64。(目前没有为其他平台构建 eBPF 程序。)
- eBPF 模式尚不支持 IPv6。
- 启用 eBPF 模式时,预先存在的连接继续使用非 BPF 数据路径;这样的连接不应该被打断,但它们并不能从 eBPF 模式的优势中受益。
- 禁用 eBPF 模式具有破坏性;通过 eBPF 数据平面处理的连接可能会中断,并且可能需要重新启动未检测和恢复的服务。
- 不支持混合集群(带有一些 eBPF 节点和一些标准数据平面节点)。(在这样的集群中,从 eBPF 节点到非 eBPF 节点的 NodePort 流量将被丢弃。)这包括具有 Windows 节点的集群。
- eBPF 模式不支持浮动 IP。
启用 eBPF 数据平面
eBPF 模式具有以下先决条件:
受支持的 Linux 发行版:
- Ubuntu 20.04(或具有更新内核的 Ubuntu 18.04.4+)。
- 带有 Linux 内核 v4.18.0-193 或更高版本的 Red Hat v8.2(Red Hat 已将所需功能向后移植到该版本)。
- 另一个支持Linux 内核 v5.3 或更高版本的发行版。
如果 Calico 没有检测到兼容的内核,Calico 将发出警告并回退到标准 linux 网络。
配置 Calico 直接与 API 服务器通信
1 | kind: ConfigMap |
禁用 kube-proxy
在 eBPF 模式下 Calico 会替换kube-proxy,执行如下命令禁用 kube-proxy
1 | kubectl patch ds -n kube-system kube-proxy -p '{"spec":{"template":{"spec":{"nodeSelector":{"non-calico": "true"}}}}}' |
开启 eBPF 模式
1 | calicoctl patch felixconfiguration default --patch='{"spec": {"bpfEnabled": true}}' |
开启 DSR 模式
D模式跳过网络中的一跳,以便从集群外部到服务(例如节点端口)的流量。这减少了延迟和 CPU 开销,但它需要底层网络允许节点使用彼此的 IP 发送流量。在 AWS 中,这要求您的所有节点都在同一个子网中,并且要禁用源/目标检查
DSR模式默认关闭;要启用它,将BPFExternalServiceModeFelix 配置参数设置为”DSR”
1 | calicoctl patch felixconfiguration default --patch='{"spec": {"bpfExternalServiceMode": "DSR"}}' |
功能比较
虽然 eBPF 数据平面具有标准 Linux 数据平面所缺乏的一些特性,但反过来也是如此:
| 元素 | 标准 Linux 数据平面 | eBPF 数据平面 |
|---|---|---|
| 吞吐量 | 专为 10GBit+ 设计 | 专为 40GBit+ 设计 |
| 第一个数据包延迟 | 低(kube-proxy 服务延迟是更大的因素) | 降低 |
| 后续数据包延迟 | 低 | 降低 |
| 在集群中保留源IP | 是 | 是 |
| 保留外部源IP | 只有externalTrafficPolicy: Local | 是 |
| 直接服务器返回 | 不支持 | 支持(需要兼容的底层网络) |
| 连接跟踪 | Linux内核的conntrack表(大小可以调整) | BPF map |
| 政策规则 | 映射到 iptables 规则 | 映射到 BPF 指令 |
| Kubernetes服务 | kube-proxy iptables 或 IPVS 模式 | BPF 程序和 map |
| IPIP | 支持 | 支持(由于内核限制没有性能优势) |
| VXLAN | 支持 | 支持 |
| 兼容其他 iptables 规则 | 是(可以在其他规则之上或之下编写规则) | 部分的; iptables 绕过工作负载流量 |
| 主机端点策略 | 支持 | 支持 |
| IPv6 | 支持 | 不支持(暂且) |
架构概述
- 传统标准数据面
从网络角度看,使用传统的iptables和路由通信时,包在内核中的转发路径如下图所示:
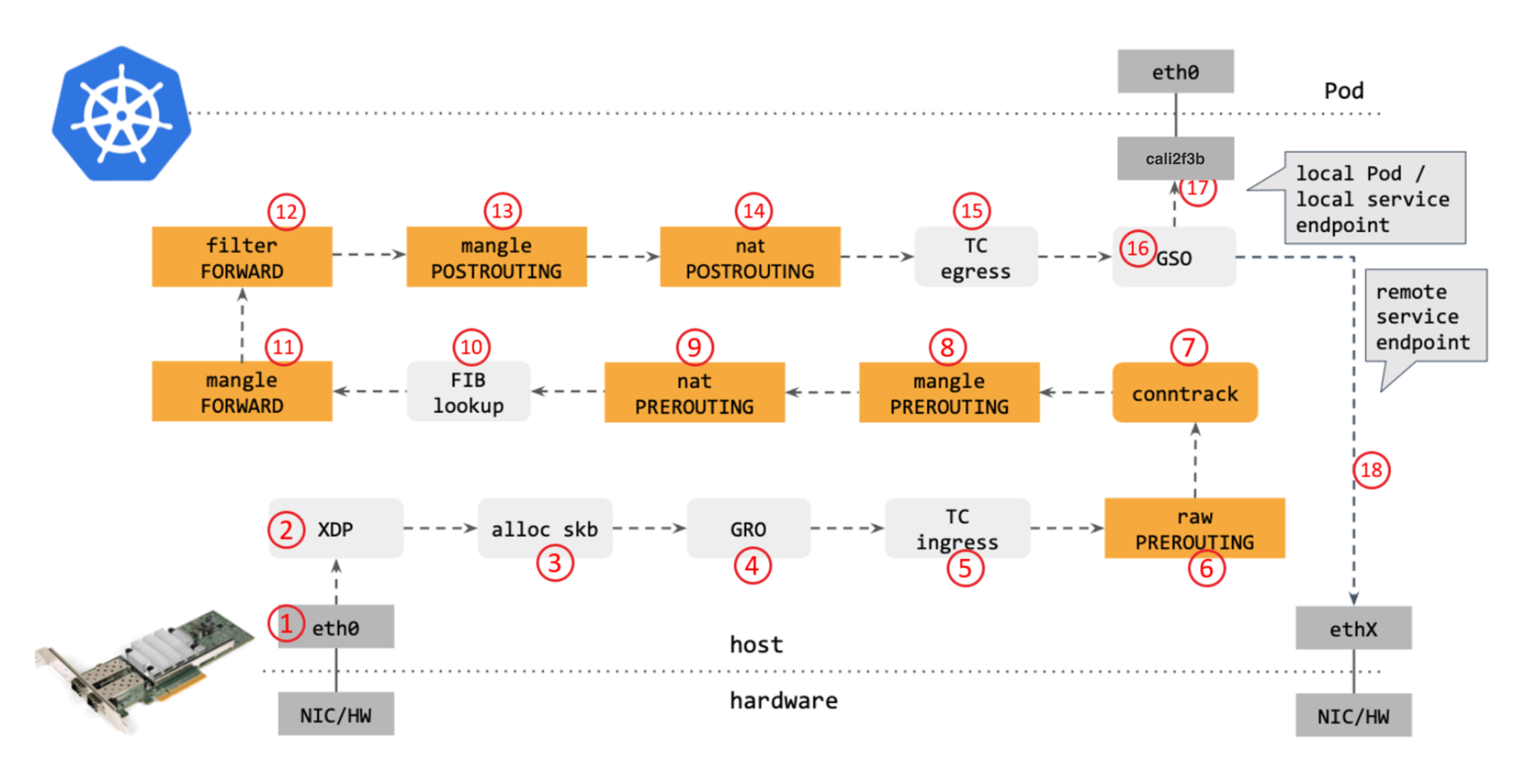
步骤:
- 网卡收到一个包(通过 DMA 放到 ring-buffer)。
- 包经过 XDP hook 点。
- 内核给包分配内存创建skb(包的内核结构体表示),然后送到内核协议栈。
- 包经过 GRO 处理,对分片包进行重组。
- 包进入 tc(traffic control)的 ingress hook。接下来,所有橙色的框都是 Netfilter 处理点。
- Netfilter:在 PREROUTING hook 点处理 raw table 里的 iptables 规则。
- 包经过内核的连接跟踪(conntrack)模块。
- Netfilter:在 PREROUTING hook 点处理 mangle table 的 iptables 规则。
- Netfilter:在 PREROUTING hook 点处理 nat table 的 iptables 规则。
- 进行路由判断(FIB:Forwarding Information Base,路由条目的内核表示) 。接下来又是四个 Netfilter 处理点。
- Netfilter:在 FORWARD hook 点处理 mangle table 里的 iptables 规则。
- Netfilter:在 FORWARD hook 点处理 filter table 里的 iptables 规则。
- Netfilter:在 POSTROUTING hook 点处理 mangle table 里的 iptables 规则。
- Netfilter:在 POSTROUTING hook 点处理 nat table 里的 iptables 规则。
- 包到达 TC egress hook 点,会进行出方向(egress)的判断,例如判断这个包是到本 地设备,还是到主机外。
- 对大包进行分片。根据 step 15 判断的结果,这个包接下来可能会:
- 发送到一个本机 veth 设备,或者一个本机 service endpoint,
- 或者,如果目的 IP 是主机外,就通过网卡发出去。
作为对比,再来看下 Calico eBPF 中的包转发路径:
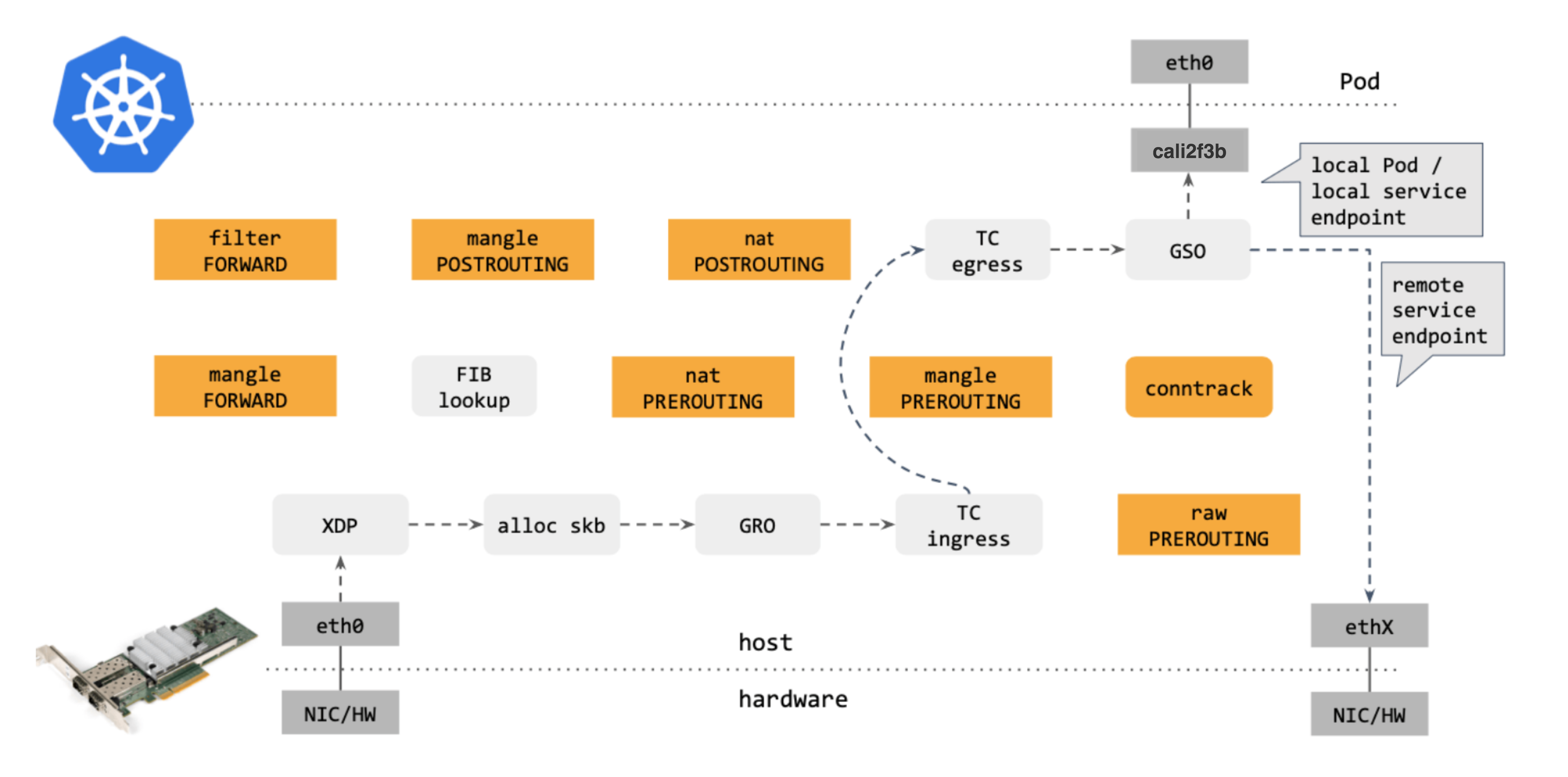
对比可以看出,Calico eBPF datapath 做了短路处理:从 tc ingress 直接到 tc egress,节省了 9 个中间步骤(总共 17 个)。更重要的是:这个 datapath 绕过了 整个 Netfilter 框架(橘黄色的框们),Netfilter 在大流量情况下性能是很差的。
- 通过 tc 级 eBPF 代理
去掉那些不用的框之后,Calico eBPF datapath 如下:
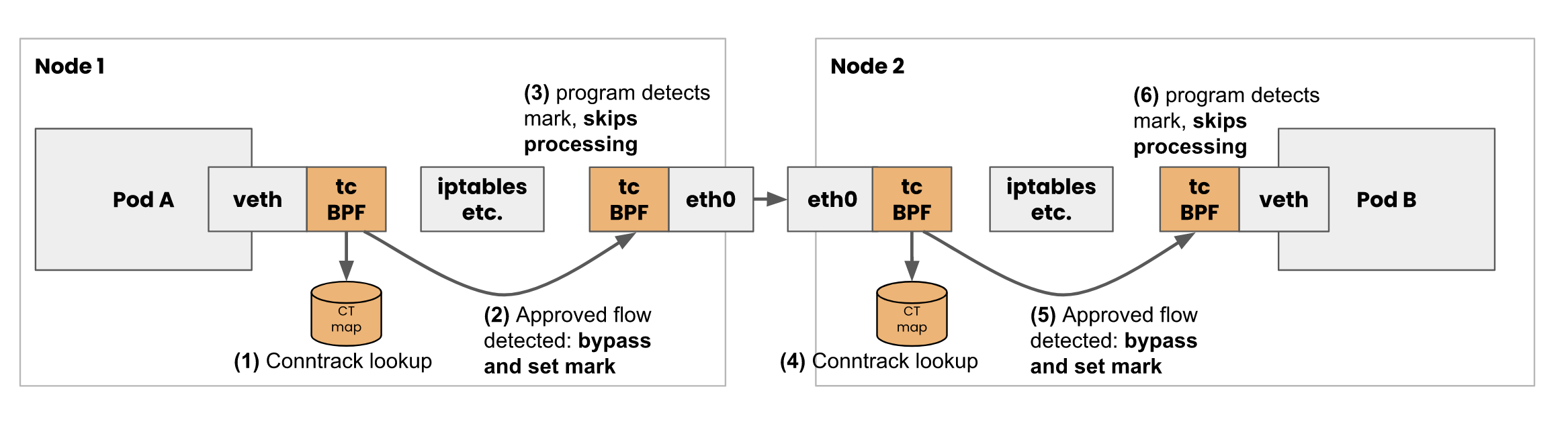
Calico 的 eBPF 数据平面将 eBPF 程序附加到tc每个 Calico 接口以及隧道接口上的hook上。这允许 Calico 及早发现工作负载数据包,并通过绕过内核通常会执行的 iptables 和其他数据包处理的快速路径来处理它们。
- 通过 socket 级 eBPF 代理
eBPF 代码可以附加在内核的不同位置(级别):
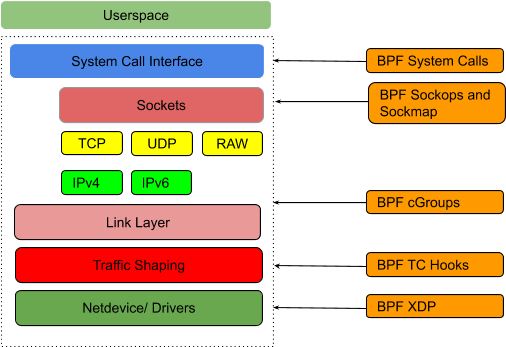
为了提高服务的性能,Calico 还通过hook到socket套接字eBPF程序来进行连接时负载平衡。当程序尝试连接到 Kubernetes 服务时,Calico 会拦截连接尝试并将套接字配置为直接连接到后端 pod 的 IP。这消除了服务连接的所有 NAT 开销。

Calico eBPF 流程
Calico 是如何用 eBPF 实现容器网络方案的。
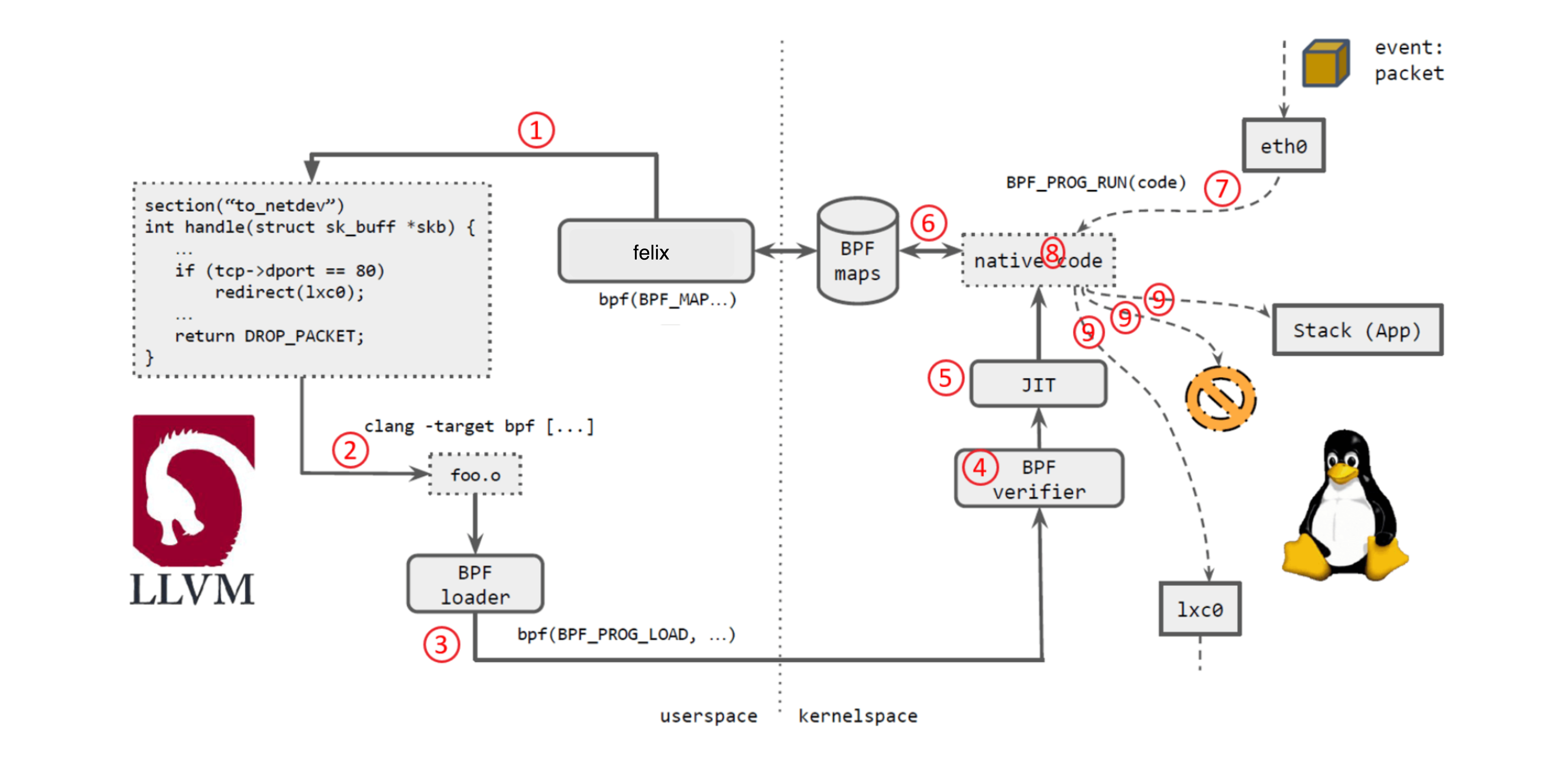
如上图所示:
- Calico felix 生成 eBPF 程序。
- 用 LLVM 编译 eBPF 程序,生成 eBPF 对象文件(object file,*.o)。
- 用 eBPF loader 将对象文件加载到 Linux 内核。
- 校验器(verifier)对 eBPF 指令会进行合法性验证,以确保程序是安全的,例如 ,无非法内存访问、不会 crash 内核、不会有无限循环等。
- 对象文件被即时编译(JIT)为能直接在底层平台(例如 x86)运行的 native code。
- 如果要在内核和用户态之间共享状态,BPF 程序可以使用 BPF map,这种一种共享存储 ,BPF 侧和用户侧都可以访问。
- BPF 程序就绪,等待事件触发其执行。对于这个例子,就是有数据包到达网络设备时,触发 BPF 程序的执行。
- BPF 程序对收到的包进行处理,例如 mangle。最后返回一个裁决(verdict)结果。
- 根据裁决结果,如果是 DROP,这个包将被丢弃;如果是 PASS,包会被送到更网络栈的 更上层继续处理;如果是重定向,就发送给其他设备。
Calico引入了多个eBPF hook点,下面重点分析 connect_time_loadbalancer,即上面讲到的东西向负载均衡:“减少服务数据包的第一个数据包延迟”
工作流程
相关的逻辑是在 Calico 的 felix 项目中实现的,入口处:felix/dataplane/linux/int_dataplane.go 的 NewIntDataplaneDriver() 函数,进行 dataplane 的初始化
首先会判断是否开启了BPF,如果是开启状态,则进行以下操作:
- 注册
map manager,该manager的作用是负责管理 ebpf 的 map(map用于userspace和kernel之间进行数据的共享) - 注册
endpoint manager,该manager的作用是负责各种ep的管理,包括host、workload等 - 创建各种map,比如nat的
frontendMap、backendMap、routeMap、conntrackMap等 - 开启
kube-proxy,此kube-proxy并非 kubernetes 的kube-proxy,而是 proxy 的一个封装,负责和kubernetes 通信,维护各种map中的信息 - 若
BPFConnTimeEnabled开启,则安装connect_time_loadbalancer,即加载相关的eBPF程序 - 启动
dataplane
下面重点看第 5 步代码是如何实现的
加载eBPF程序
入口 bpf/nat/connecttime.go 的 InstallConnectTimeLoadBalancer() 函数
1 | func InstallConnectTimeLoadBalancer(frontendMap, backendMap, rtMap bpf.Map, cgroupv2 string, logLevel string) error { |
进入 installProgram() 函数,看如何加载程序
1 | func installProgram(name, ipver, bpfMount, cgroupPath, logLevel string, maps ...bpf.Map) error { |
下图是加载 attach bpf 程序后,用户进程调用 socket api 时的路径。在建立 connect、recvmsg、sendmsg 时都会经过这个程序进行处理。而这个ebpf程序所做的工作就是:判断是否要访问的是 k8s service,如果是的话,直接将请求转发到后端的pod上,这样就不在需要做nat了,节省了所有的nat开销。即实现了:“减少服务数据包的第一个数据包延迟”
接下来看看bpf程序是如何实现的,共实现三个 section bpf-gpl/connect_balancer.c
1 | __attribute__((section("calico_connect_v4"))) // section 1:在建立connection时,做nat转发,将请求转发至后端的pod |
实际的 nat 操作是 do_nat_common() 来做的
1 | static CALI_BPF_INLINE void do_nat_common(struct bpf_sock_addr *ctx, uint8_t proto) |
官方性能测试
Pod到Pod的吞吐量和CPU
使用qperf测量在不同节点上运行的一对Pod之间的吞吐量。由于大部分网络开销都是按数据包计算的,因此同时测试了1440字节MTU和8940字节MTU(其中MTU是最大数据包大小;对于互联网流量而言,实际值为1500;在某些数据中心中为9000;并且都减少了如果是在重叠式网络的顶部运行,请保守估计为60)。测量了吞吐量和CPU使用率。
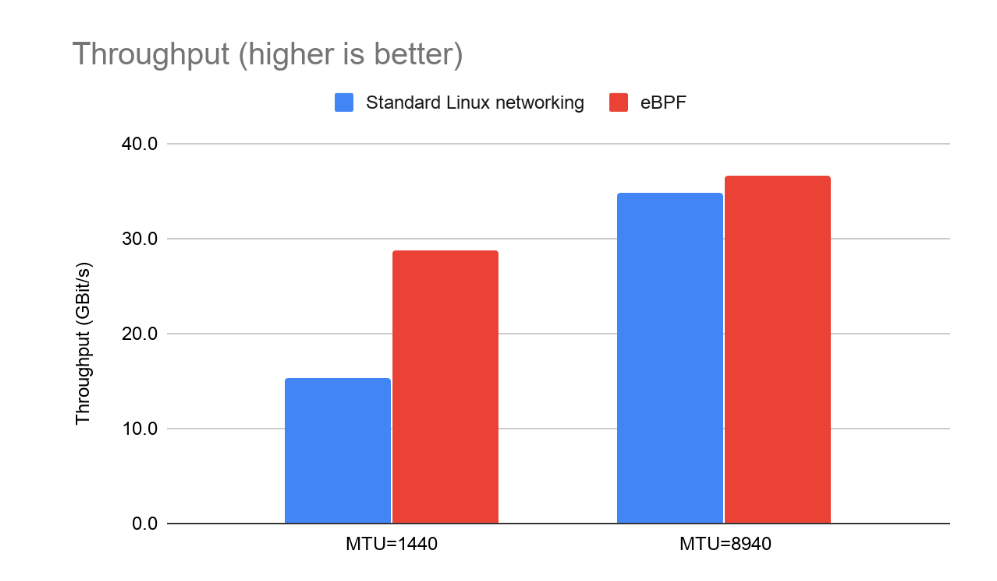
对于 8940 MTU,这两个选项都接近饱和 40Gbit 链路。在较小的数据包大小下,我们看到吞吐量出现了差距。
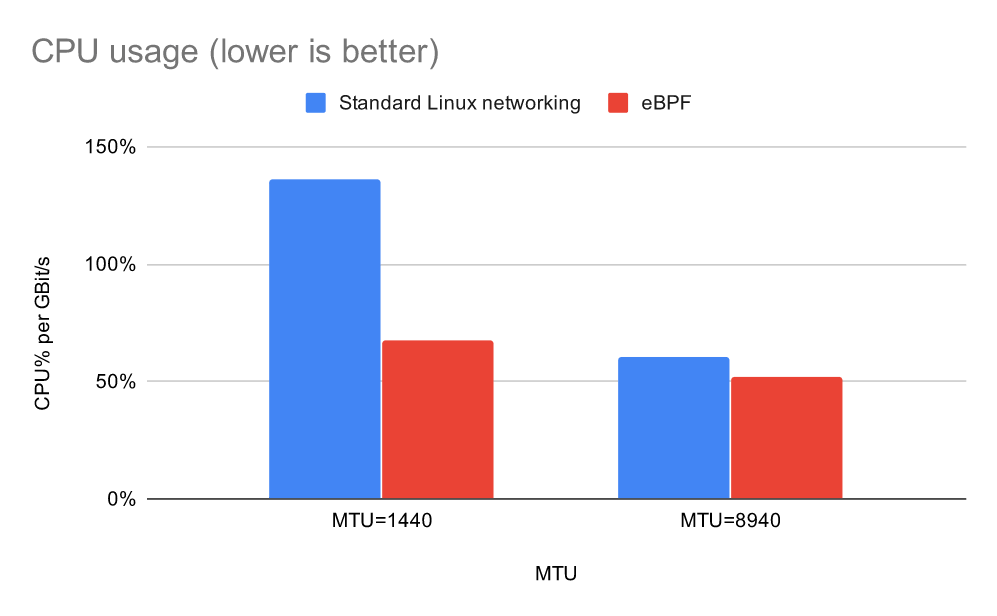
将每 GBit 的 CPU 使用率标准化后,eBPF 数据平面每 GBit 使用的 CPU 比标准 Linux 网络数据平面少得多,在小数据包大小时优势最大。
改进 kube-proxy
对于 kube-proxy 和我们的实现,只有新流中的第一个数据包需要付出代价,才能确定流将负载均衡到哪个 pod。(后续数据包采用 conntrack 快速路径,这与您正在运行的服务数量无关。)为了测量第一个数据包延迟的影响,我们使用 curl 并打开详细调试输出来测量到 nginx 的“连接时间”荚。这是进行 TCP 握手交换的时间(每个方向一个数据包)。
我们改变了服务的数量,并在 IPVS 和 iptables 模式下使用 kube-proxy 以及我们的 eBPF 数据平面运行了测试。
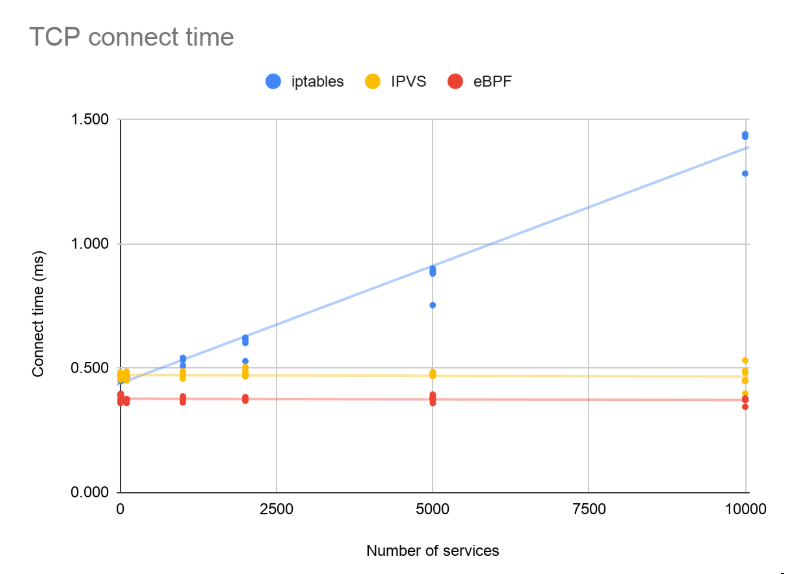
在 iptables 模式下,kube-proxy 的实现使用随服务数量增长的规则列表。因此,随着服务数量的增加,它的延迟会变得更糟。IPVS 模式和我们的实现都使用了高效的地图查找,随着服务数量的增加,性能曲线变得平坦。
将这些数字放在上下文中很重要。虽然 IPVS 和我们的 eBPF 模式比其他模式更快,但这只是第一个数据包。如果您的工作负载正在重用连接(通常是 gRPC 或 REST API 的情况),或者传输一个 1MB 的文件,那么此更改所节省的半毫秒将不会很明显。另一方面,如果您的工作负载涉及数千个短暂的、对延迟敏感的连接,您将看到真正的收益。
高效的数据平面更新
当服务更新时,kube-proxy 必须更新内核中的 iptables 或 IPVS 状态。使用 eBPF,能够更有效地更新数据平面。
下图显示了测试期间的整个节点 CPU 使用情况
- 从 5000 个静态服务开始,每个服务由 5 个 pod 支持
- sleep 90s 以获得基线
- 100s 内只流失一项服务
- sleep 90s
kube-proxy 配置了默认的 30 秒最大同步间隔。所有数据平面都配置了 1 秒的最小同步间隔
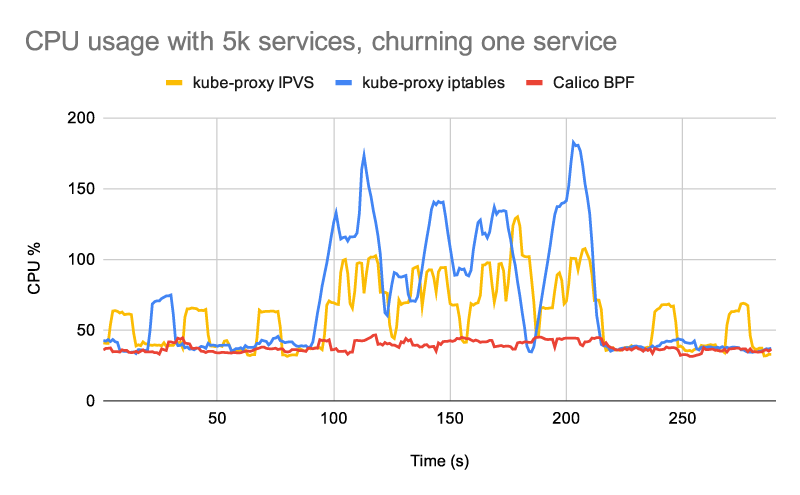
正如预期的那样,对于 5k 服务,您可以看到 IPVS 模式下的 kube-proxy 使用更少的 CPU 来保持数据平面的同步,而不是 iptables 模式下的 kube-proxy。(如果推动更多数量的服务或服务端点,两者之间的差距会变得更大。)相比之下,我们新的 eBPF 数据平面具有更高效的控制平面,在任何一种模式下使用的 CPU 都比 kube-proxy 少,即使在非常大量的服务。
参考
- 有关 eBPF 数据平面的更多信息和性能指标,请参阅 公告博客文章。
- 如果您想在 Kubernetes 集群中尝试 eBPF 模式,请遵循 启用 eBPF 数据平面指南。
- XDP开发 eBPF XDP:基础知识和快速教程
